Rebuilding Devin for Claude Sonnet 4.5: Lessons and Challenges
We rebuilt Devin for Claude Sonnet 4.5.
The new version is 2x faster, 12% better on our Junior Developer Evals, and it's available now in Agent Preview. For users who prefer the old Devin, that remains available.
Why rebuild instead of just dropping the new Sonnet in place and calling it a day? Because this model works differently—in ways that broke our assumptions about how agents should be architected. Here's what we learned:
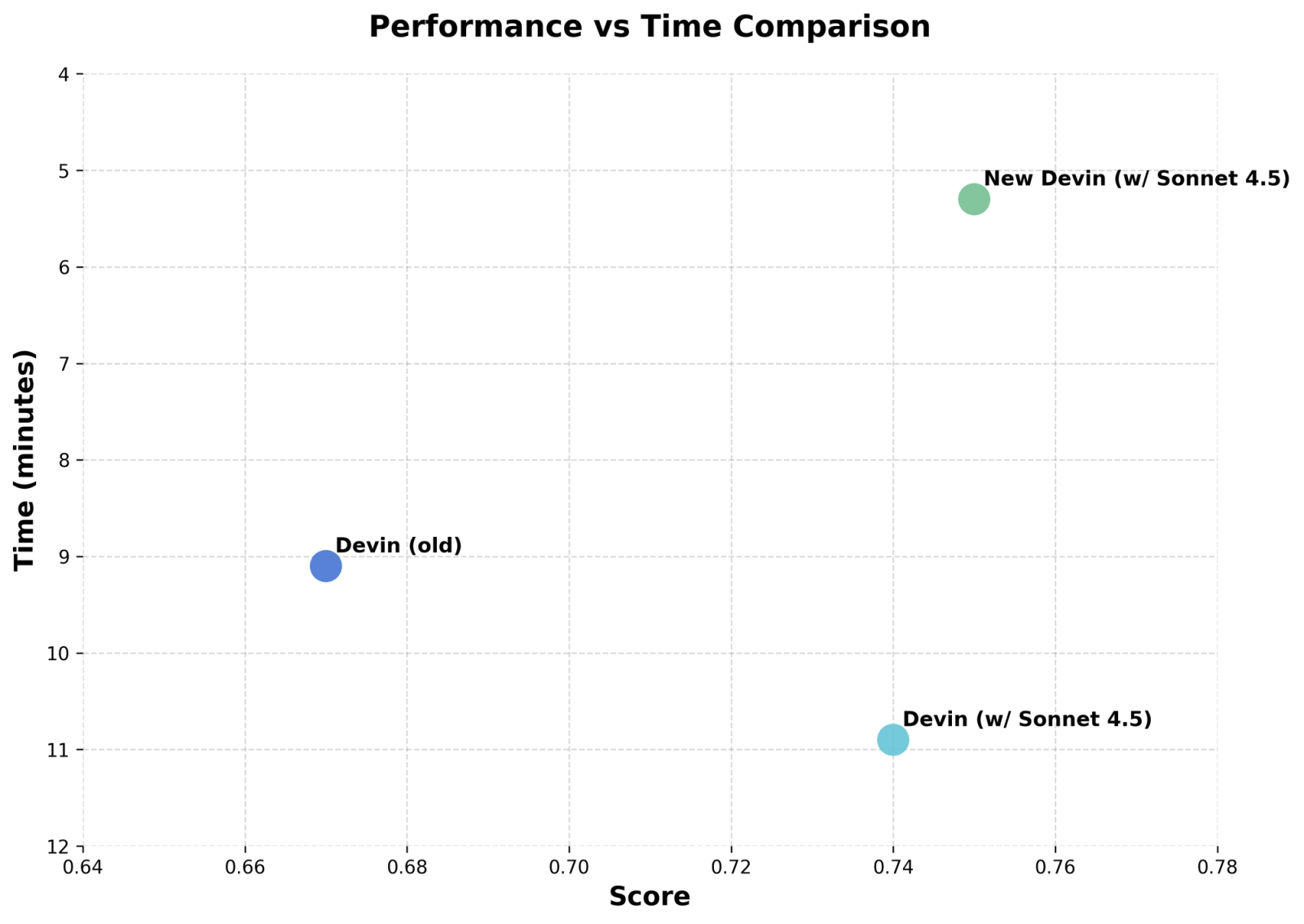
Because Devin is an agent that plans, executes, and iterates rather than just autocompleting code (or acting as a copilot), we get an unusual window into model capabilities. Each improvement compounds across our feedback loops, giving us a perspective on what's genuinely changed. With Sonnet 4.5, we're seeing the biggest leap since Sonnet 3.6 (the model that was used with Devin's GA): planning performance is up 18%, end-to-end eval scores up 12%, and multi-hour sessions are dramatically faster and more reliable.
In order to get these improvements, we had to rework Devin not just around some of the model’s new capabilities, but also a few new behaviors we never noticed in previous generations of models. We are sharing some of our observations below:
The model is aware of its context window
Sonnet 4.5 is the first model we've seen that is aware of its own context window, and this shapes how it behaves. As it approaches context limits, we've observed it proactively summarizing its progress and becoming more decisive about implementing fixes to close out tasks.
This "context anxiety" can actually hurt performance: we found the model taking shortcuts or leaving tasks incomplete when it believed it was near the end of its window, even when it had plenty of room left.
We ended up prompting pretty aggressively to override this behavior. Even then, we found that prompts at the start of the conversation weren't enough—we had to add reminders both at the beginning and the end of the prompt to keep it from prematurely wrapping up.
When researching ways to address this issue, we discovered one unexpected trick that worked well: enabling the 1M token beta but cap usage at 200k. This gave us a model that thinks it has plenty of runway and behaves normally, without the anxiety-driven shortcuts or degraded performance.
This behavior has has real implications for how we architect around context management. When planning token budgets, we now need to factor in the model's own awareness: knowing when it will naturally want to summarize versus when we need to intervene with context compaction.
Interestingly, the model consistently underestimates how many tokens it has left—and it's very precise about these wrong estimates.
The model takes a lot of notes
One of the most striking shifts in Sonnet 4.5 is that it actively tries to build knowledge about the problem space through both documentation and experimentation.
Writing notes for itself
The model treats the file system as its memory without prompting. It frequently writes (or wants to write) summaries and notes (e.g. CHANGELOG.md, SUMMARY.md, but not CLAUDE.md nor AGENTS.md), both for the user and its own future reference. This suggests the model has been trained to externalize state rather than rely purely on context. This behavior is more pronounced when the model is closer to the end of its context window.
When we saw this, we were interested in the possibility to potentially remove some of our own memory management and let the model handle it. But in practice, we found the summaries weren't comprehensive enough. For example, it would sometimes paraphrase the task, leaving out important details. When we relied on the model's own notes without our compacting and summarization systems, we saw performance degradation and gaps in specific knowledge: the model didn't know what it didn't know (or what it might need to know in the future). It's very likely that these notes can be improved with prompting. You just shouldn't think you get a perfect system for free.
In some cases, somewhat humorously, we've seen the agent spend more tokens writing summaries than actually solving the problem. We've also noticed that the model's level of effort is uneven: the model tends to generate more summary tokens the shorter the context window.
In our testing, we found this behavior useful in certain cases, but less effective than our existing memory systems when we explicitly directed the agent to use its previously generated state.
This is an interesting paradigm and a new axis for model development, especially for simpler agent architectures or systems built around subagent delegation. It's clearly a new direction from Anthropic: likely pointing toward a future where models are more context-aware and where this becomes the way multiple agents communicate with each other. The RL training hasn't fully progressed to the point where this is reliable yet, but we'll be tracking how it evolves.
Testing to create feedback loops
Sonnet 4.5 is notably more proactive about writing and executing short scripts and tests to create feedback loops, and shows good judgment about when to use this capability. This generally improves reliability on long-running tasks, though we've occasionally seen it attempt overly creative workarounds when debugging. For example, when editing a React app, we’ve noticed the models getting the HTML of the page in order to check their work along the way in order to ensure that the behavior was correct. In another case, when trying to fix a seemingly innocent error related to two local servers trying to run on the same port, the model ended up using this behavior to create an overly complicated custom script instead of addressing the root cause issue (terminating the process).
The model works in parallel
Sonnet 4.5 is efficient at maximizing actions per context window through parallel tool execution -running multiple bash commands at once, reading several files simultaneously, that sort of thing. Rather than working strictly sequentially (finish A, then B, then C), the model will overlap work where it can. It also shows decent judgment about self-verification: checking its work as it goes.
This is very noticeable in Windsurf, and was an improvement upon Devin's existing parallel capabilities. That being said, there are tradeoffs. Parallelism burns through context faster, which leads to the context anxiety we mentioned earlier. But when the model is running with an empty context window, this more concurrent approach makes sessions feel faster and more productive. It's a subtle shift, but one that influenced how we thought about the architecture.
The model also seems to be trained to burn through parallel tool calls faster when it is earlier on in its context window, but takes more cautious as it nears the limit. This suggests to us that its been trained to be aware of how many output tokens its tool calls will produce.
What we're exploring next
These behaviors open up many interesting avenues, and we haven't been able to explore them all yet. Here are some we're eager to continue testing:
- Subagents and context-aware tool calls. The model's improved judgment about when to externalize state and create feedback loops suggests it might handle subagent delegation more effectively. However, as we've learned you have to be very careful about when to use subagents because the context and state management gets complex quickly. Sonnet 4.5 seems more aware of the right types of tasks to delegate, which could make this more practical.
- Meta-agent prompting. We're particularly interested in how this model handles meta-level reasoning about agent workflows. Early experiments suggest it works well with verification systems — letting the model reason about its own development process rather than just executing tasks.
- Context-management models. Sonnet 4.5 seems to have some initial intuition around how to mange its own context. It might be possible that custom-trained models for intelligent context management could both result in faster and better performance.
We'll be sharing more as we learn what works (and what doesn't). In the meantime, we’re excited for you to try both the new Devin with Sonnet 4.5 and Windsurf.





