Kevin-32B: Multi-Turn RL for Writing CUDA Kernels
Carlo Baronio*, Pietro Marsella*, Ben Pan*, Silas Alberti
Stanford University, Cognition AI
*equal contribution

Coding is an iterative process – you write a program, execute it, evaluate the results, and refine your code based on the feedback. Recent advances in LLM for code generation have tried to incorporate this process at inference-time, using methods like parallel sampling. While these methods are effective, they rely on search without actual learning — the model weights are frozen.
We explore reinforcement learning in a multi-turn setting, using intermediate feedback from the environment, and masking model thoughts to avoid exploding context over multiple turns.
Our model, Kevin-32B = K(ernel D)evin, outperforms frontier reasoning models on kernel generation. Moreover, our results show that multi-turn training makes the model more effective at self-refinement compared to single-turn training.
Multi-Turn Training Method
We use KernelBench, a dataset of 250 PyTorch-based classic deep learning tasks. It measures a model’s ability to replace the PyTorch operators with optimized CUDA kernels. We focus on the first two levels, each containing 100 tasks. Level 1 includes foundational tasks such as matrix multiplication, convolution, and loss functions, while level 2 consists of fused operators. We train on 180 tasks of these two levels, with a holdout set of 20 tasks.
During training, the model goes through an iterative feedback loop: we extract feedback from a generated kernel and have the model refine it. If the kernel fails to compile, we pass the model the error trace and ask it to fix it. If it’s correct, we measure the runtime and ask the model to improve it further.
Our initial approach constructs the trajectories as follows. Starting with the initial prompt, we append the chain of thought, kernel, and evaluation information after each refinement step. We then assign a single reward to the entire trajectory—defined as the maximum score achieved by any kernel—and use this sequence for training.
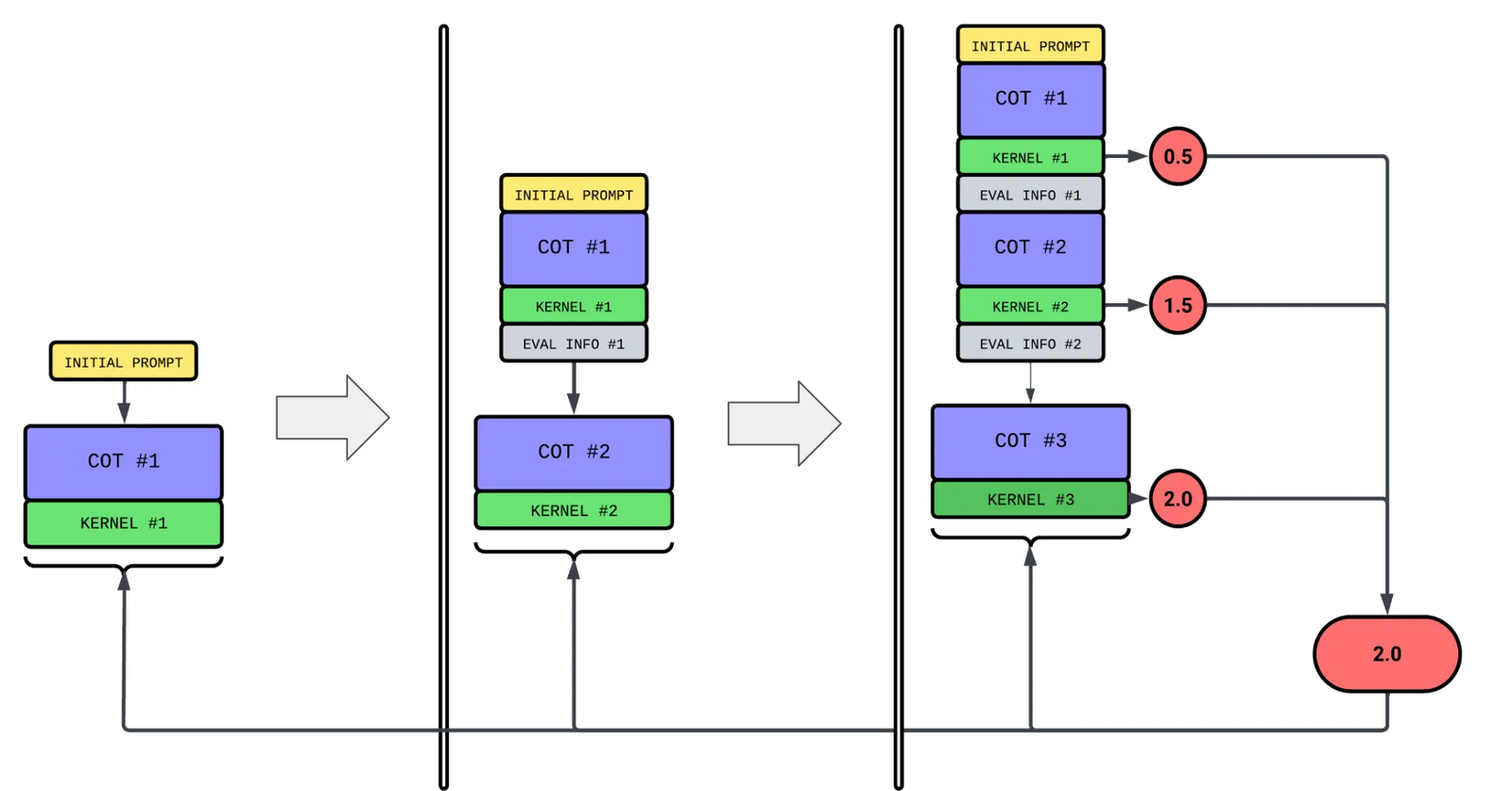
However, this approach presents several problems:
- Exploding context window: reasoning models generate long chains of thought. With this approach, the length of the trajectory can easily reach 50-100k tokens after just a few passes, becoming prohibitive for training.
- Sample inefficiency and credit assignment: we are assigning a single reward for the entire trajectory even though we generated multiple kernels. This provides no signal on which refinement step actually improved correctness or performance. The rewards should be assigned to refinement steps based on their contribution to the final result.
To fix the exploding context length, we discard the longest part of the trajectory — the chain of thought. Each prompt will now only include the previously generated kernels and evaluation results. To still retain information about the thinking process of the previous step, we ask the model to generate a brief summary of its own thought process, which is then passed to the subsequent contexts.
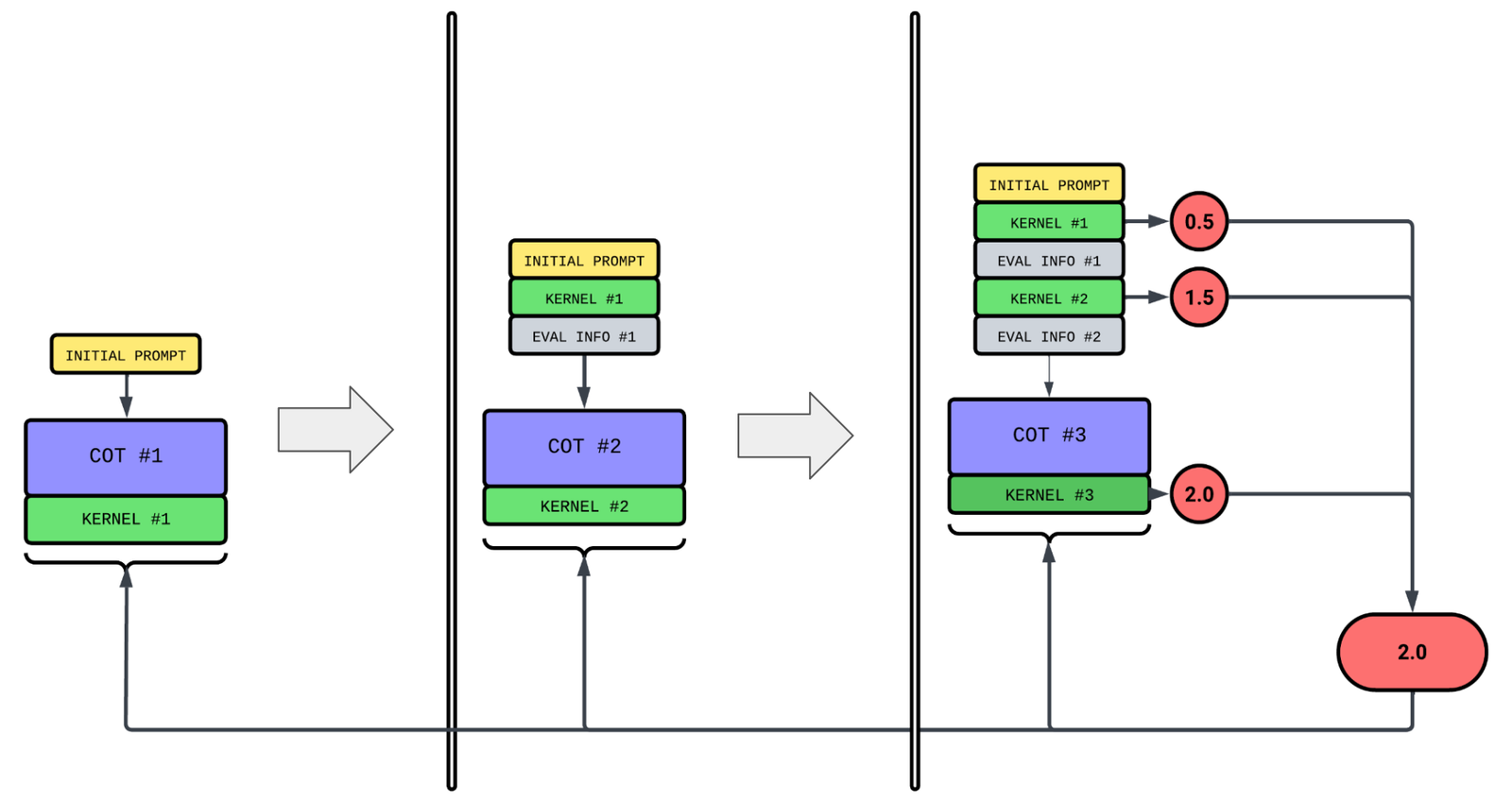
fix #1: remove chain of thought for inference
To address sample inefficiency, we choose a more expressive reward function. We model the refinement of kernels as a Markov decision process, setting the reward of a given response as the discounted sum of scores of the current kernel and all subsequent ones. Each refinement step thus becomes its own training sample.
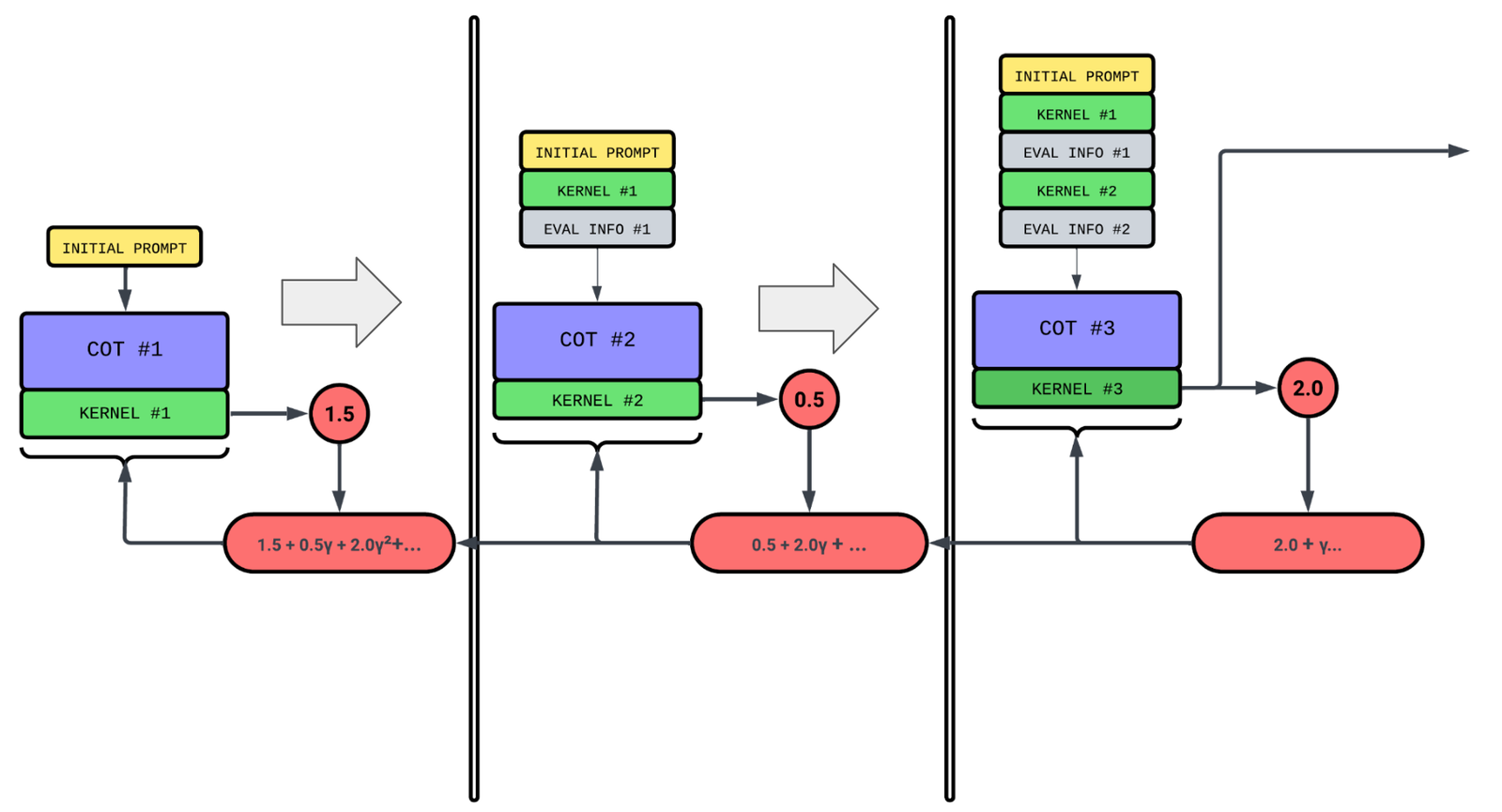
fix #2: reward as a discounted sum of scores
Results
For each task, we sample 16 trajectories in parallel with 8 serial refinement steps. A trajectory's correctness is 1 if it contains at least one kernel that passes the unit tests and 0 otherwise. Its performance score is the speedup over reference implementation of the fastest correct kernel. For each task’s correctness or performance, we define best@16 as the maximum across all trajectories and avg@16 as the mean across the trajectories.
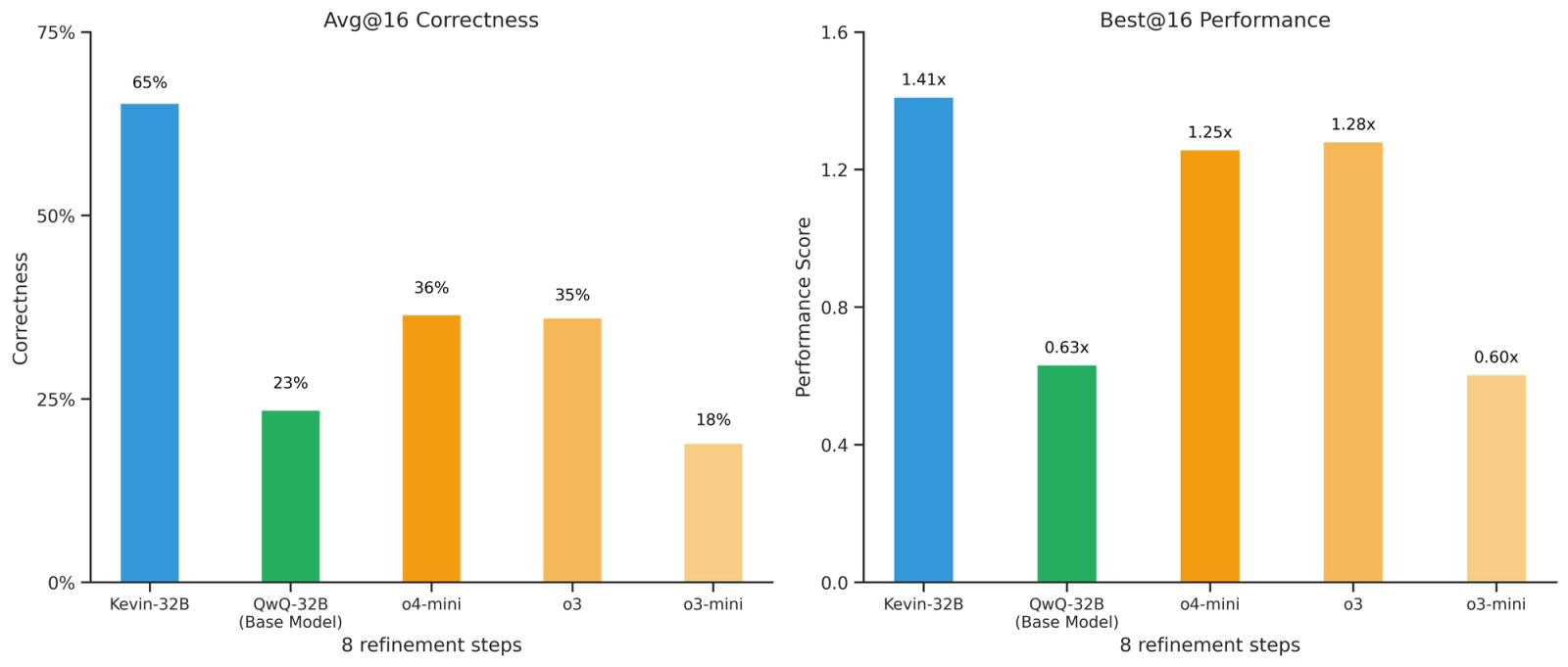
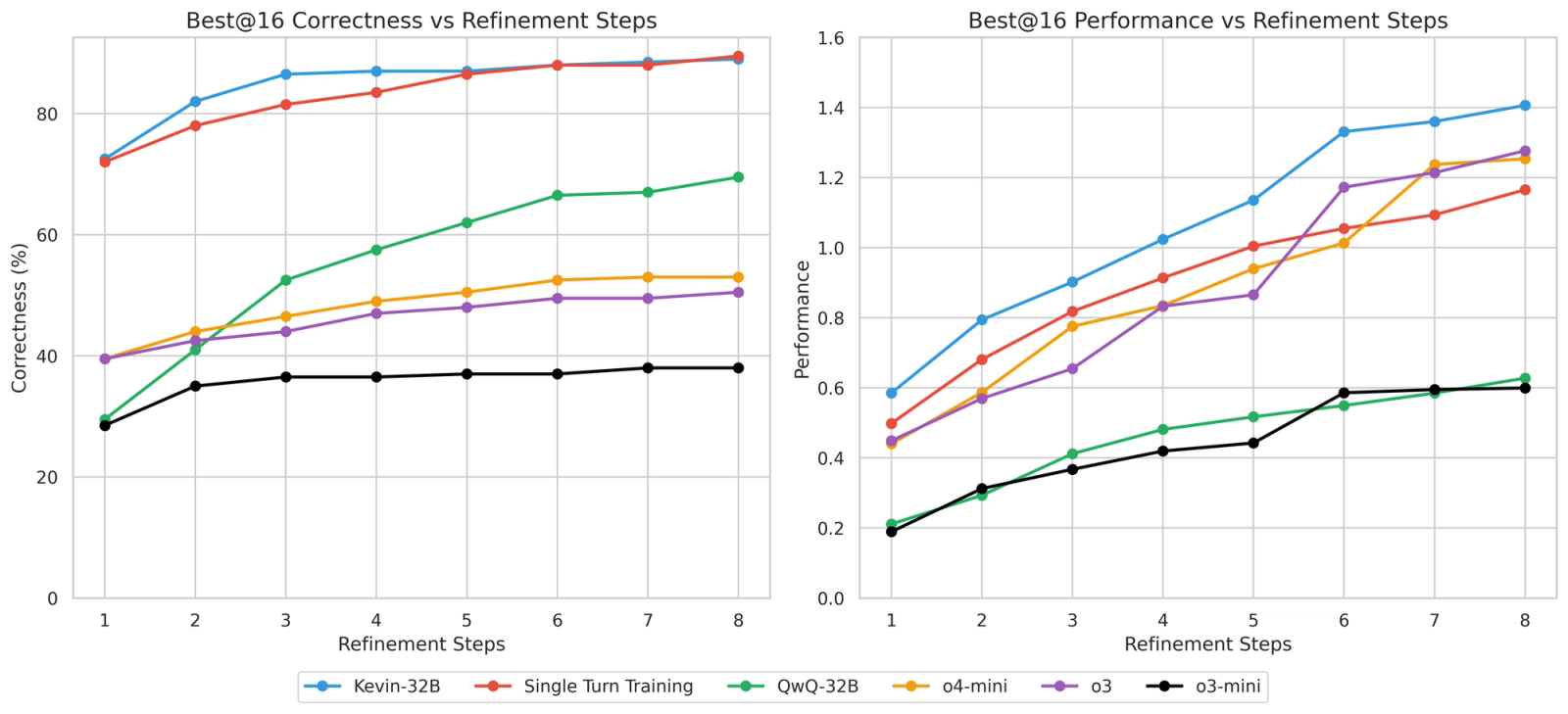
Given 8 refinement steps, Kevin-32B gets 65% of its attempts correct on average across the entire dataset, significantly surpassing QwQ-32B and frontier models. It solves 89% of the dataset, whereas o4-mini and o3 only solve 53% and 51%, respectively. Across the dataset, Kevin-32B achieves a best@16 speedup of 1.41x, outperforming frontier models.
Kevin-32B is especially effective on level 2 tasks, achieving avg@16 correctness of 48% (vs 9.6% on o4-mini and 9.3% on o3). This suggests multi-turn training improves the model’s ability to solve more challenging tasks with longer horizons. Similarly, we notice that our model is very effective on level 2 tasks, achieving a best@16 speedup of 1.74x (vs 1.2x on o4-mini and o3).
Since the holdout set only contains 20 tasks, the evaluation results have high variance. Thus, we focus our discussions on the results on the entire dataset. As shown both here and in the Test-Time Search section, the trained model performs even better on the holdout set, showing generalization to unseen tasks.
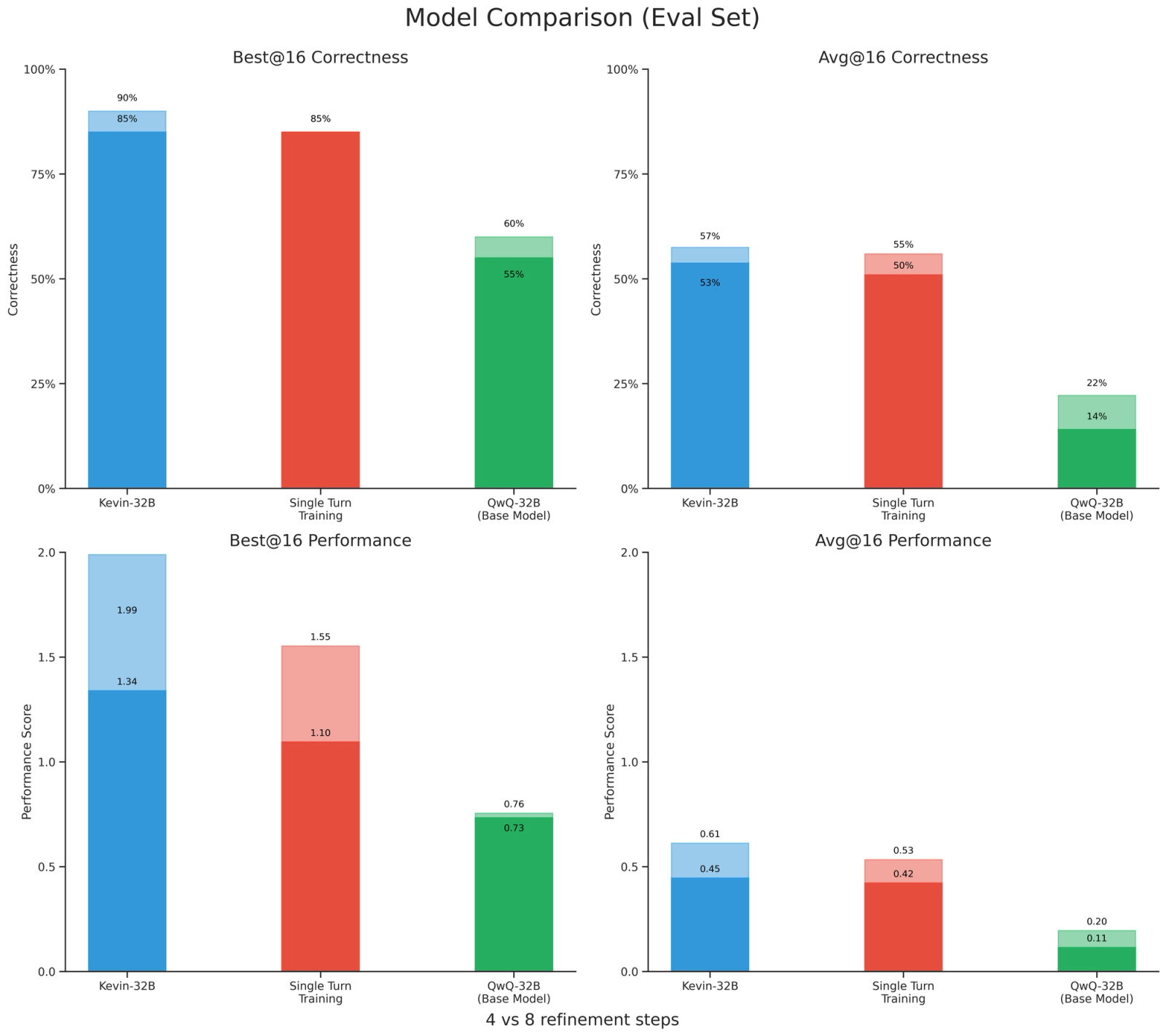
Multi-Turn vs Single-Turn
Kevin-32B also demonstrates massive improvements over QwQ-32B and the single-turn trained model. At 4 refinement steps, Kevin-32B marginally outperforms the single turn model, but the gap between them widens as we increase to 8 refinement steps. This shows that multi-turn training scales better over the serial axis by encouraging more aggressive optimizations.
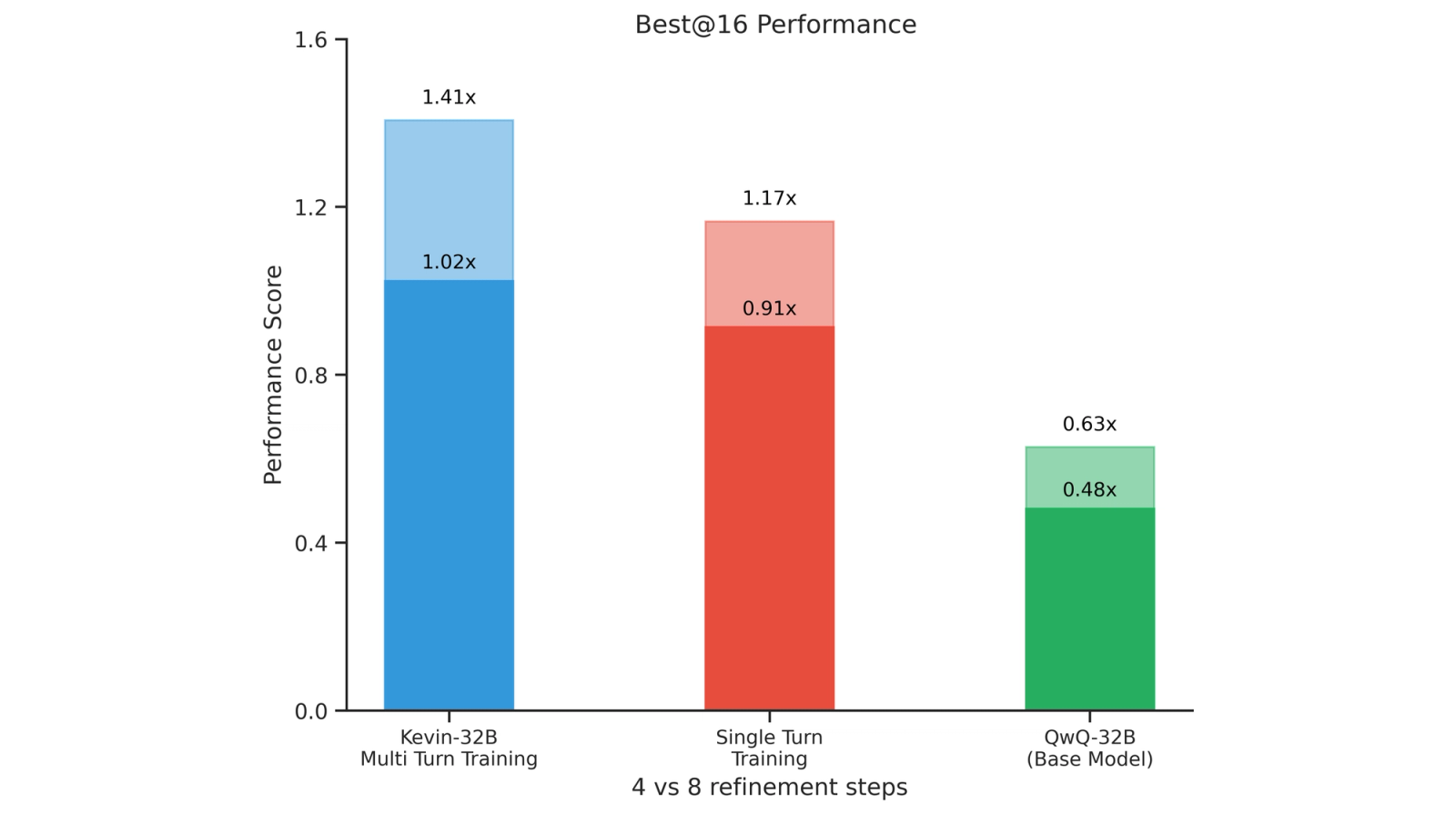
One might wonder if the single-turn trained model can achieve better speedups by sampling parallel trajectories instead. However, we found that it’s not the case for this environment. Given a fixed compute budget, multi-turn inference dominates over single-turn inference, even for the single-turn trained model. Check the Single-Turn Inference section for details.
Reward Hacking
Our initial experiments used smaller models like DeepSeek-R1-Distill-Qwen-7B, which led to several instances of reward hacking:
- The model simply copies the PyTorch reference implementation, thus getting rewarded for generating a correct answer with 1.0x speedup.
- The model wraps an incorrect implementation of the CUDA kernel in a try-except statement and invokes the PyTorch implementation functions as fallback.
- The model inherits from the reference implementation, bypassing the need for a CUDA implementation.
Examples of reward hacking

To prevent reward hacking, we impose stricter format checks on the responses. We assign a reward of 0 to responses that use PyTorch functions or that do not contain CUDA kernels.
We observe that reward hacking occurs when the gap between the model capabilities and the dataset difficulty is significant. The model struggles to solve any task, so when it generates a hacked kernel, it’s the only action with a positive advantage, and thus gets reinforced significantly.
Junk and Repetition
Across several runs, we observe that around steps 35–40, the model begins generating repetitive or nonsensical responses. We hypothesize that this is because the model has deviated into a region of instability. Surprisingly, we stumbled upon a strong predictor for future junk — the proportion of responses whose chain of thought did not start with “Okay,” — which we called the “Not Okay Ratio”.
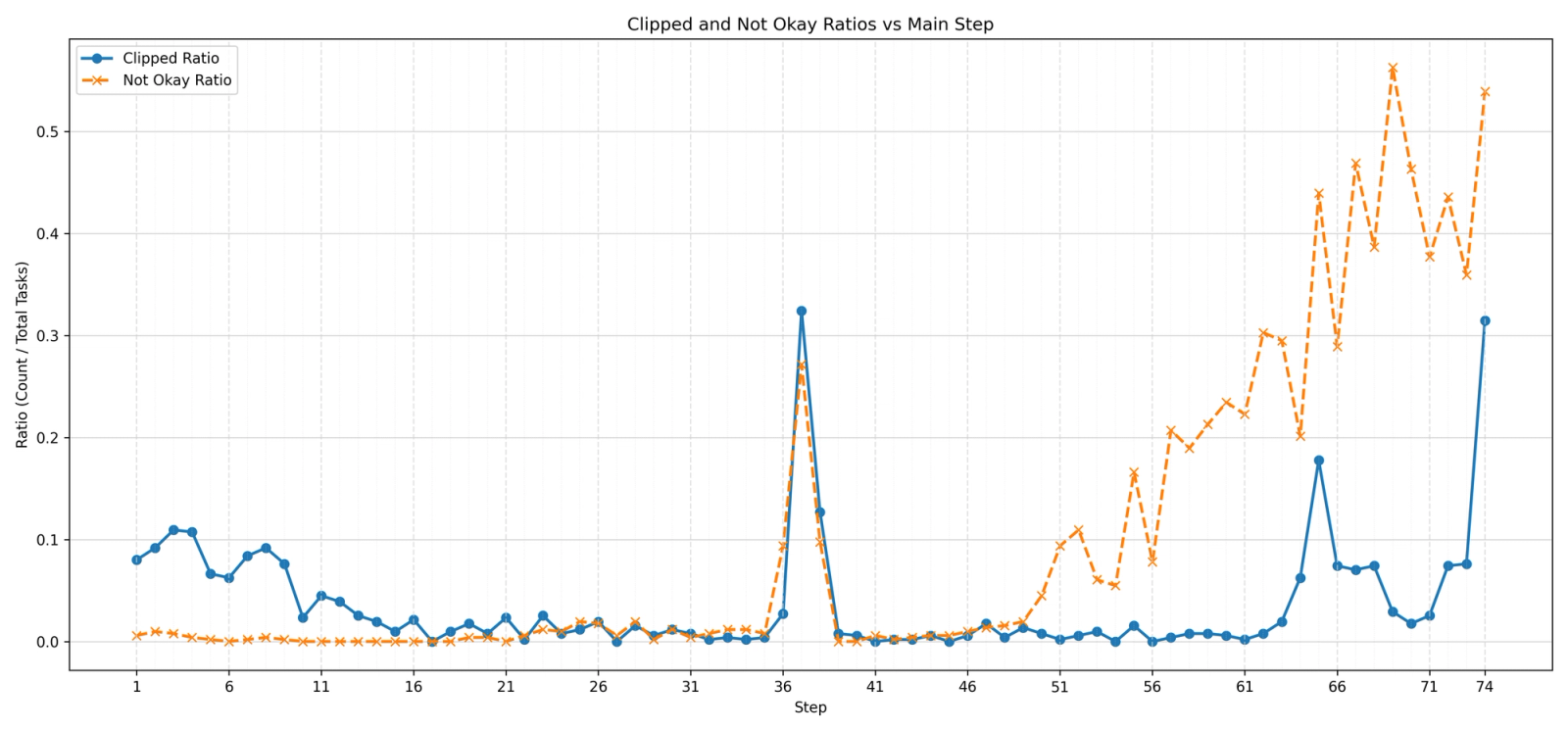
The more the model trains, the more the beginning of the CoT becomes erratic:
"Okay Amigos, so I need to optimize this 3D tensor-matrix multiplication..”
"Okay Holy crap, I need to get this code optimized….”
At the 8th pass of the refinement step:
"Okay SHIT, this is getting frustrating. Let me see. The error is about …”
To fix this problem, we attempted runs with KL coefficients of 0.001 and 0.01 but found that it slows down learning while not preventing junk generation. At the end we were able to delay the onset of junk until step 100 by using constant length loss normalization from Dr. GRPO, which lowered the grad norm significantly, and by clipping the grad norm aggressively at 0.05.
Sample Kernel
As an example, we look at a trajectory of level 1 task 40 (LayerNorm). We highlight how the model iteratively incorporates feedback from the kernel evaluation and uses that to improves its generations.
Step 1: the model generates a correct kernel. It uses shared memory and fuses the computation of mean/variance with normalization. This achieves a speedup of 0.6x.
...
__shared__ float shared_sums[512]; // 256 threads * 2 values
...
for (int s = block_size / 2; s > 0; s >>= 1) {
if (tid < s) {
shared_sums[2 * tid] += shared_sums[2 * (tid + s)];
shared_sums[2 * tid + 1] += shared_sums[2 * (tid + s) + 1];
}
__syncthreads();
}
...
for (int d = tid; d < D; d += block_size) {
float x_val = x[n * D + d];
float y_val = (x_val - mean) / sqrt_var;
y_val = y_val * scale[d] + bias[d];
y[n * D + d] = y_val;
}
...Step 2: the model notices from the evaluation feedback that “The current speedup is 0.6, which means it's actually slower than the PyTorch version. That's not good. Let me think about where the bottleneck might be”. It spends most of its reasoning tokens looking for a better block size and modifies the code accordingly. The change is correct, and the speedup is now 4.27x.
Steps 3 and 4: the model attempts even more aggressive optimizations. It thinks about loop unrolling and reducing bank conflicts but settles on warp-level intrinsics. But it fails — first due to a correctness issue in the reduction logic, then due to an overlong chain of thought.
Step 5: the model notices the issue in the incorrect warp-reduction implementation and fixes it. It implements a two level warp reduction succesfully. The final speedup is 9.61x.
// Warp-level reduction using shuffle instructions
for (int delta = 1; delta <= 16; delta <<= 1) {
float other_sum = __shfl_xor_sync(0xFFFFFFFF, warp_sum, delta);
float other_sum_sq = __shfl_xor_sync(0xFFFFFFFF, warp_sum_sq, delta);
warp_sum += other_sum;
warp_sum_sq += other_sum_sq;
}
__shared__ float sum_warp[32];
__shared__ float sum_sq_warp[32];
__shared__ float results[2]; // [mean, inv_std]
if (warp_id == 0) {
sum_warp[warp_lane] = warp_sum;
sum_sq_warp[warp_lane] = warp_sum_sq;
}
__syncthreads();
// Final reduction within the first warp (tid 0-31)
if (tid < 32) {
float my_sum = sum_warp[tid];
float my_sum_sq = sum_sq_warp[tid];
// Reduce within the first warp (32 threads)
for (int s = 16; s >= 1; s >>= 1) {
my_sum += __shfl_xor_sync(0xFFFFFFFF, my_sum, s);
my_sum_sq += __shfl_xor_sync(0xFFFFFFFF, my_sum_sq, s);
}
...
}The full kernel is present in the appendix.
Training Setup
We use Group Relative Policy Optimization (GRPO), introduced by DeepSeek as a variant of the popular Proximal Policy Optimization (PPO) algorithm. Instead of using a value network to estimate the baseline and calculate the advantage, GRPO normalizes the rewards within the group of responses sampled from the same prompt.
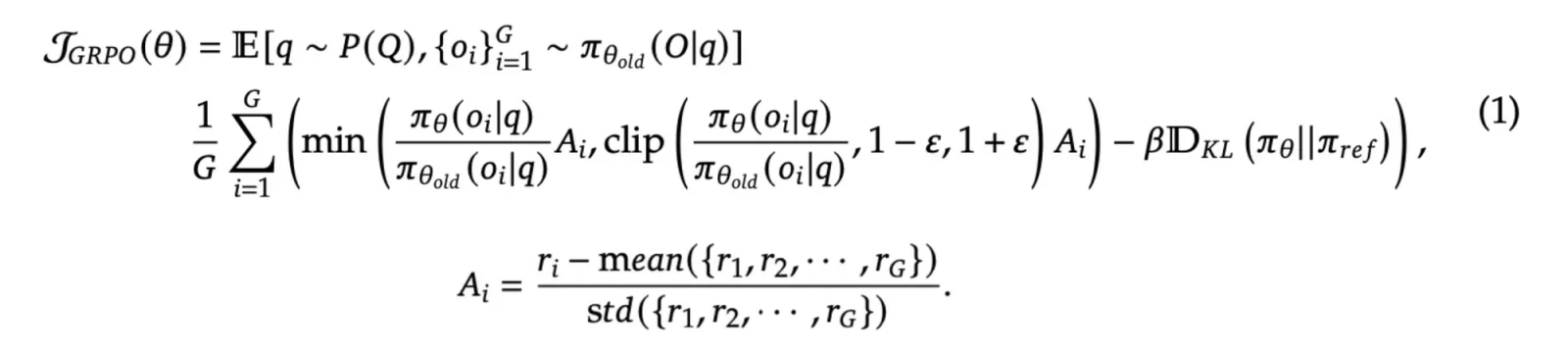
We use vLLM for inference and DeepSpeed Zero-3 for offloading optimizer states. We train with 8 tasks per batch and 16 trajectories per task. We use GRPO with 2 gradient steps per batch. Our base model is QwQ-32B
After the response generation is done, each GPU offloads its vLLM engine to CPU memory and evaluates the kernels it generated. For each response, we check if the response is formatted correctly and extract the CUDA kernel. We then compile and execute the code to test for correctness with randomized tensors. If correct, we profile the kernel’s runtime.
Responses receive 0.3 reward for passing the correctness checks and an additional performance reward equal to the speedup obtained over the reference implementation.
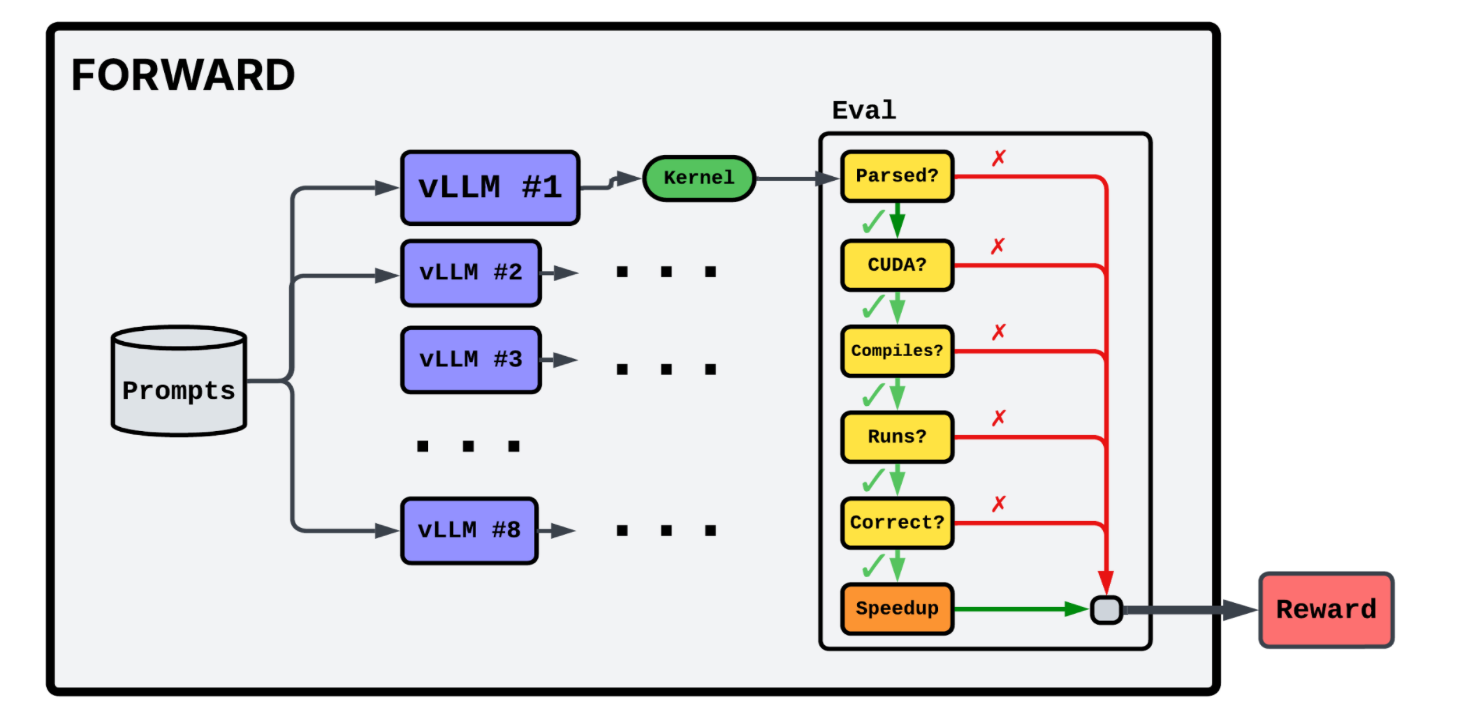
Kernel Evaluation & Benchmark Issues
We sandboxed evaluation so that fatal errors, such as CUDA illegal memory accesses, do not crash the training process.
Because many tasks in KernelBench use very small input tensors, the benchmark ends up measuring kernel‑launch overhead more than actual kernel execution time. To address this, we enlarged the tensor dimensions of the affected tasks.
A sneakier bug in the KernelBench’s evaluation harness caused the tested kernel to recycle the output tensor from the reference implementation as its own tensor output. As a result of this, a kernel that only computes (correctly) a portion of the output tensor would still pass the correctness check. We address this by first running the tested kernel and then the reference implementation, thus avoiding this hack.
Single-Turn Training Setup
We use max_grad_norm = 0.5, lr = constant 2e-6 with warmup ratio 0.03, max_prompt_length = 8192, max_response_length = 16384. We use Clip-High from DAPO with eps_high = 0.28. We set the KL coefficient to 0 to allow the model to deviate freely from the base policy.
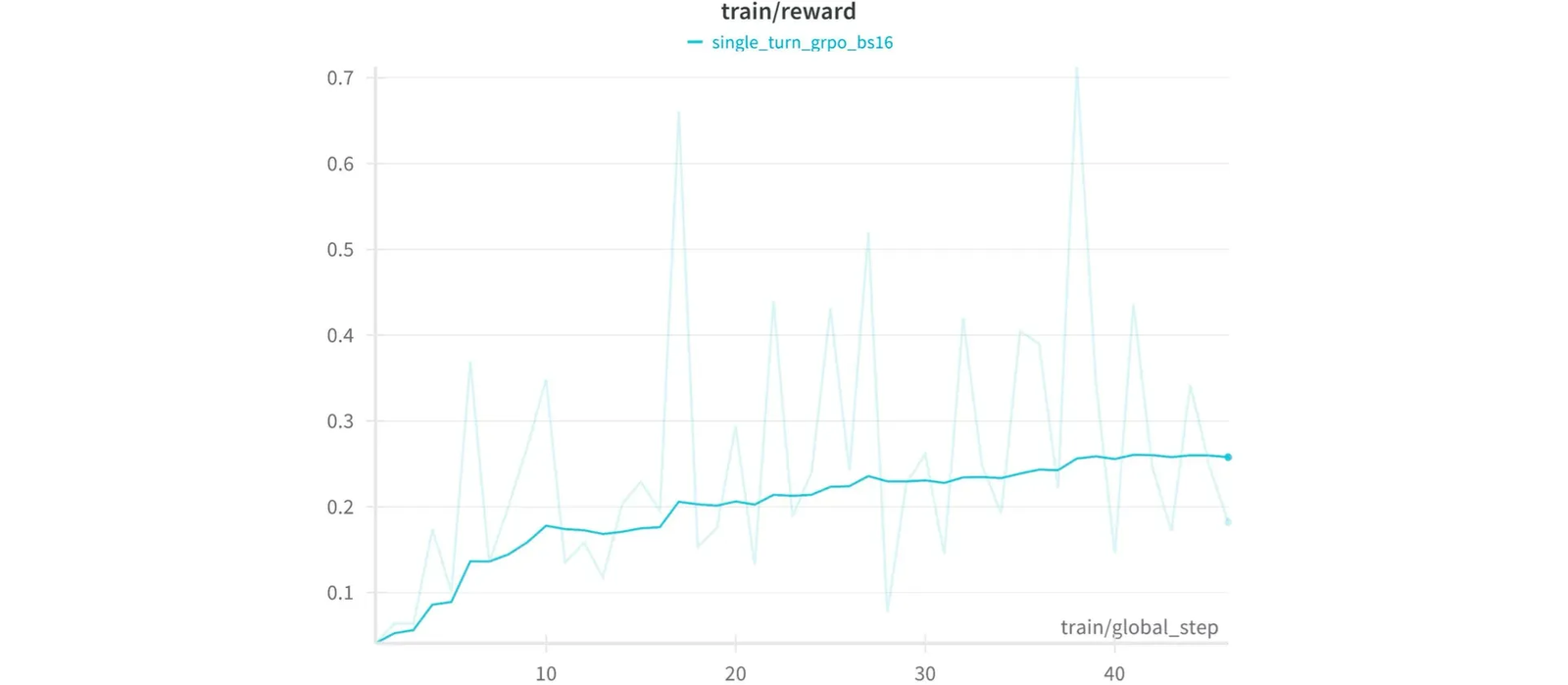
We observe that the single turn model improves significantly over the base model, but the reward starts to plateau after 25 steps.
Multi-Turn Training Setup
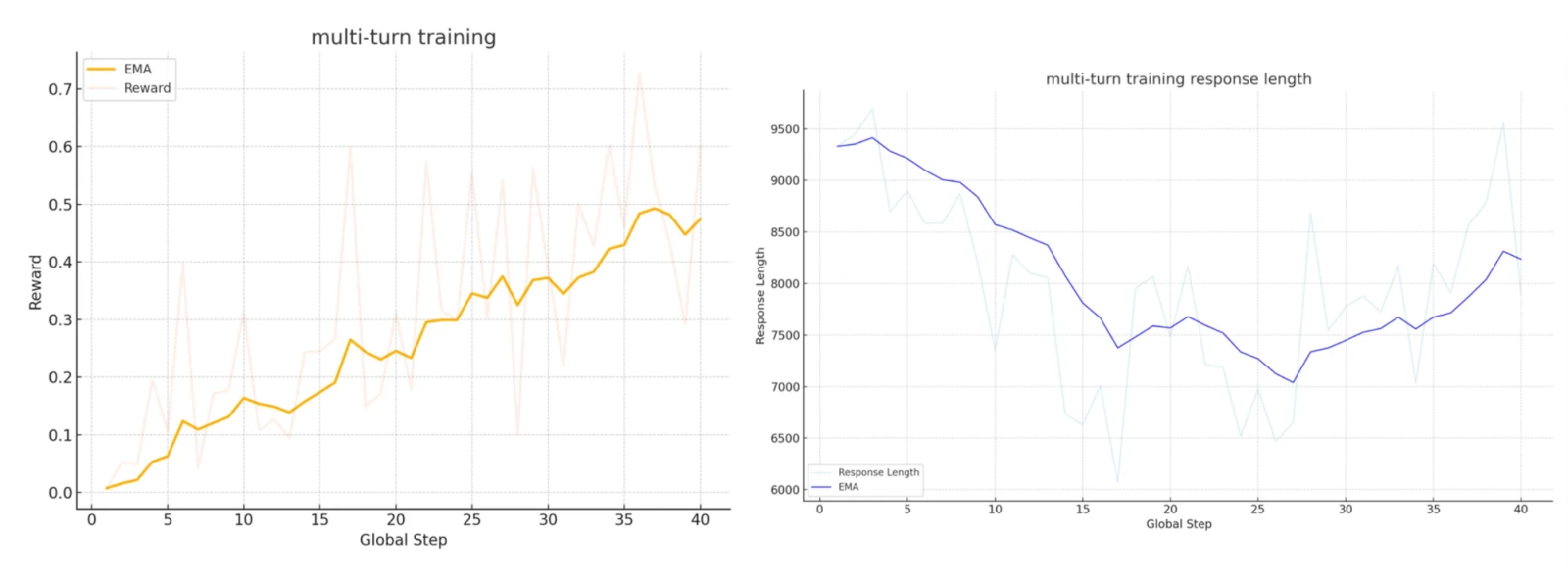
We score the correctness and performance of each trajectory by its best kernel. When a kernel is not correct, the performance score of that kernel is 0. In our final training run each forward pass consists of 16 parallel trajectories with 4 refinement steps each, and a discount factor of 0.4. Unlike in single turn training, the reward now steadily increases.
The response length initially decreases as the model learns to use its reasoning tokens more efficiently for kernel generation. After step 25, the response length increases as the model attempts more sophisticated solutions. Following DeepScaleR, we extend the max response length from 16K to 22K tokens at step 30.
More Results & Ablations
Inference Time Scaling
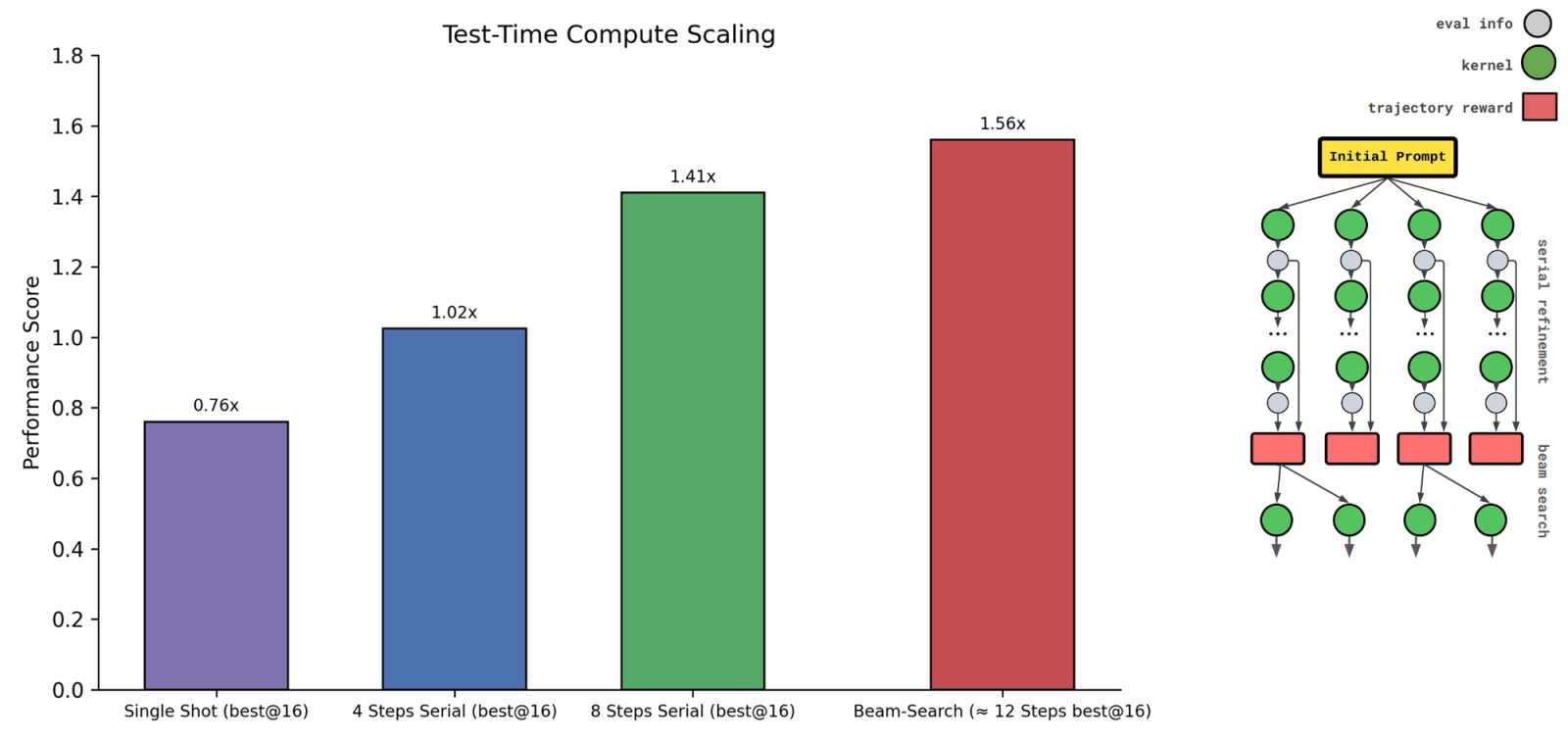
We also investigated scaling along the parallel and serial axes for our multi-turn model. For our first experiment at inference time, we used 16 parallel trajectories with 8 refinement steps. Again, we see the multi-turn model scales better with more refinement steps.
For our second experiment, we increased the number of parallel trajectories to 64 while keeping only 4 refinement steps. This achieves best@64 correctness of 89.5% and performance of 1.28x, slightly worse than best@16 for 8 refinement steps.
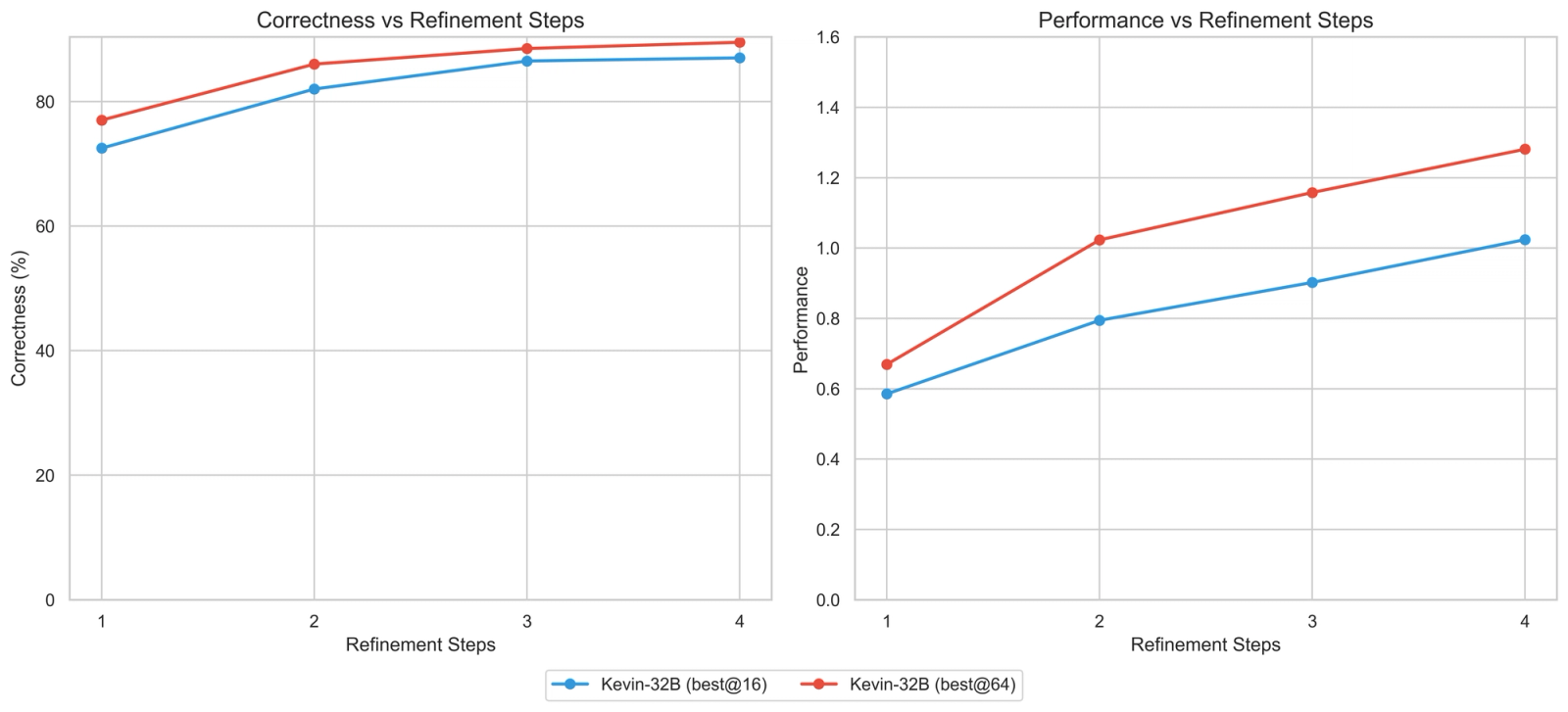
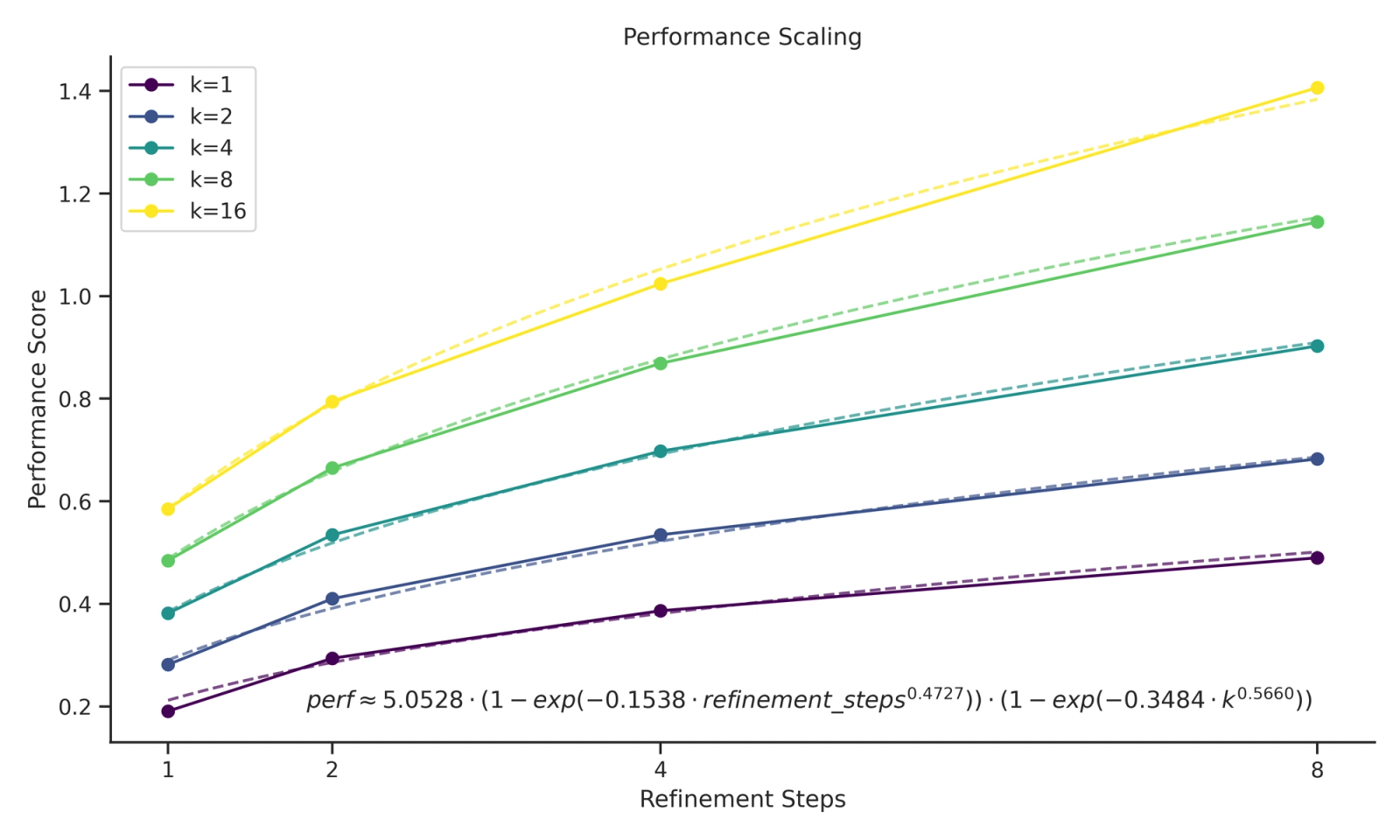
We investigate the effects of scaling inference along the parallel or serial axis. We use pass@k performance that represents the estimated performance of k generations. We compute the metric using an unbiased estimator similar to Chen et al. that has a lower variance than avg@k.
We then try to find a suitable law to model our experimental data. We notice that the contribution from both refinement steps and parallel trajectories looks like a power law at this (small) order of magnitude. Moreover, the performance metric should saturate since kernel speedups are finite. Hence, we decided to fit the following law (which presents a power law behavior at small orders of magnitude and gets diminishing returns as the amount of compute increases):

We find that given a fixed, non-trivial inference compute budget (e.g. refinement steps * parallel trajectories ≥ 8), the optimal compute allocation is shifted towards serial refinement rather than parallel generation.
Single-Turn Model Inference
We previously compared the multi-turn model (Kevin-32B) and the single-turn model in the same multi-turn inference setting. But since the single-turn model was trained in a single-turn setting, a natural questions that arises is the following: given a fixed amount of compute for a model trained in a single-turn setting, can we get better inference results with single-turn inference or multi-turn inference?
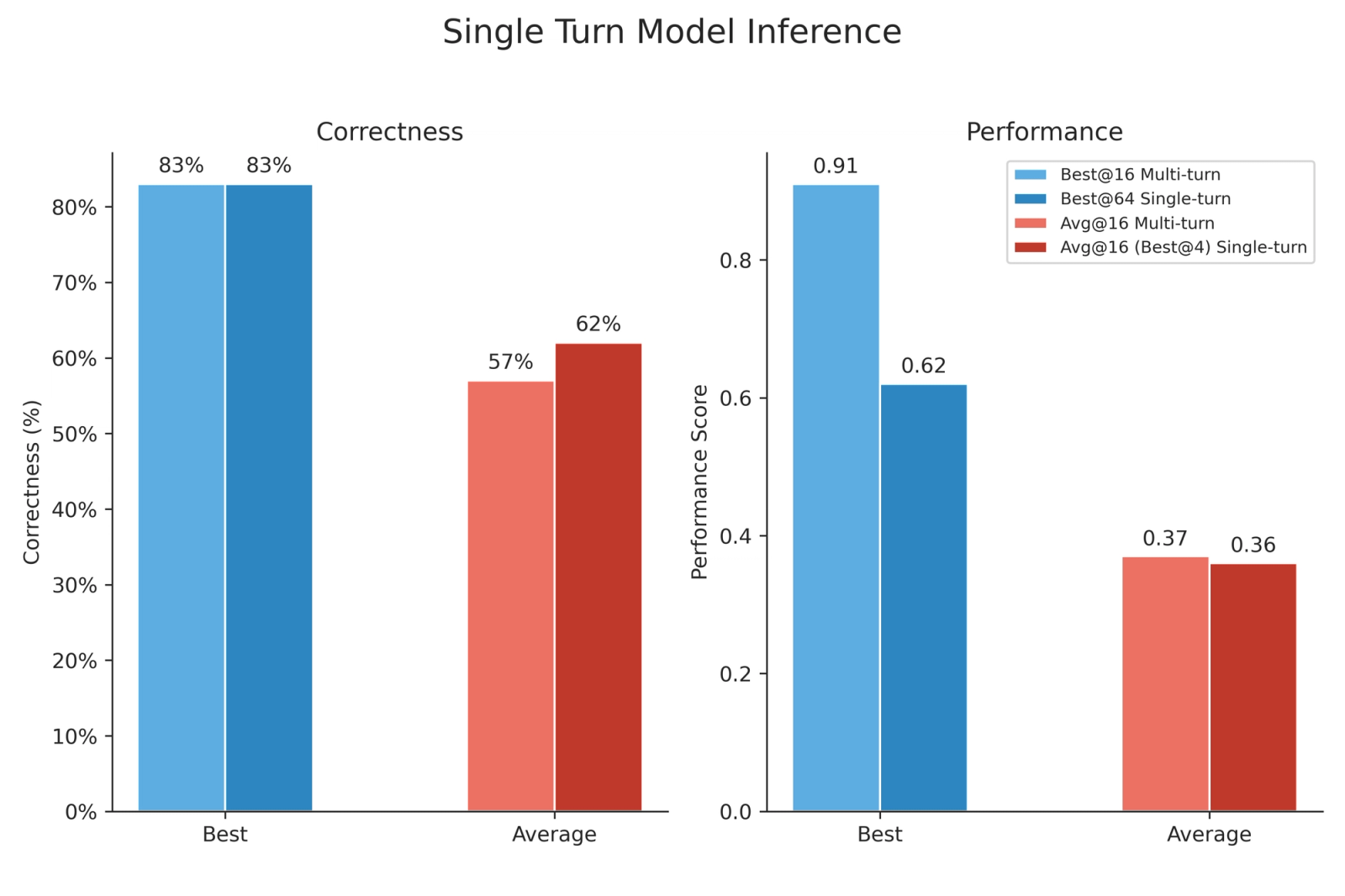
For this particular environment, multi-turn inference gives generally better results than single-turn inference even when using a single-turn trained model (except for average correctness). To compare the two methods we evaluate the single-turn model with 64 parallel trajectories and only 1 step, and then compare the results to the multi-turn inference with 16 parallel trajectories and 4 refinement steps per trajectory. We split the 64 parallel trajectories for single-turn inference in 16 groups of 4 kernels, take the best@4 for each group, and average across the 16 groups. This way we can compare this metric with avg@16 from multi-turn inference (since in that case we are taking best@4 across a single trajectory). Finally we compare best@64 for single-turn inference with best@16 (4 refinement steps) for multi-turn inference.
Reward Shaping
We experimented with reward shaping. For runs on smaller models, we added intermediate rewards (successful parsing, compilation, execution, …) to guide the model. However, we found that they may distract the model from updating towards the true objective — generating correct and performant kernels. We also experimented with a length penalty, as suggested by Kimi, but found that it degrades the performance of the model in our setting.
For multi-turn training, we ran ablations on different reward functions. We experimented with different gamma values (0.4 vs 0.8) and how we aggregate rewards across a single trajectory — either summing or taking the maximum.
In kernel generation, we fundamentally care about obtaining the kernel with the maximum trajectory (rather than optimizing for the discounted sum of scores of several kernels). We thus thought that using the max formula for reward would lead to better speedups.
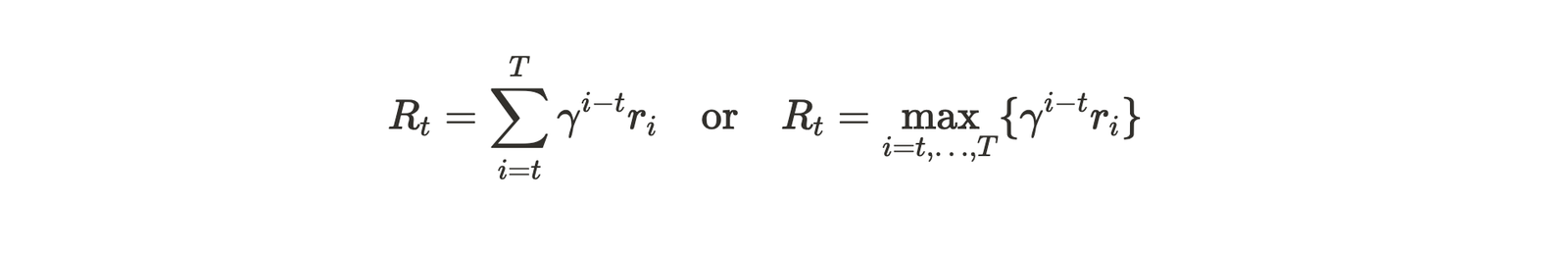
We were surprised, however, to find that that summing rewards across the MDP with gamma=0.4 worked the best.
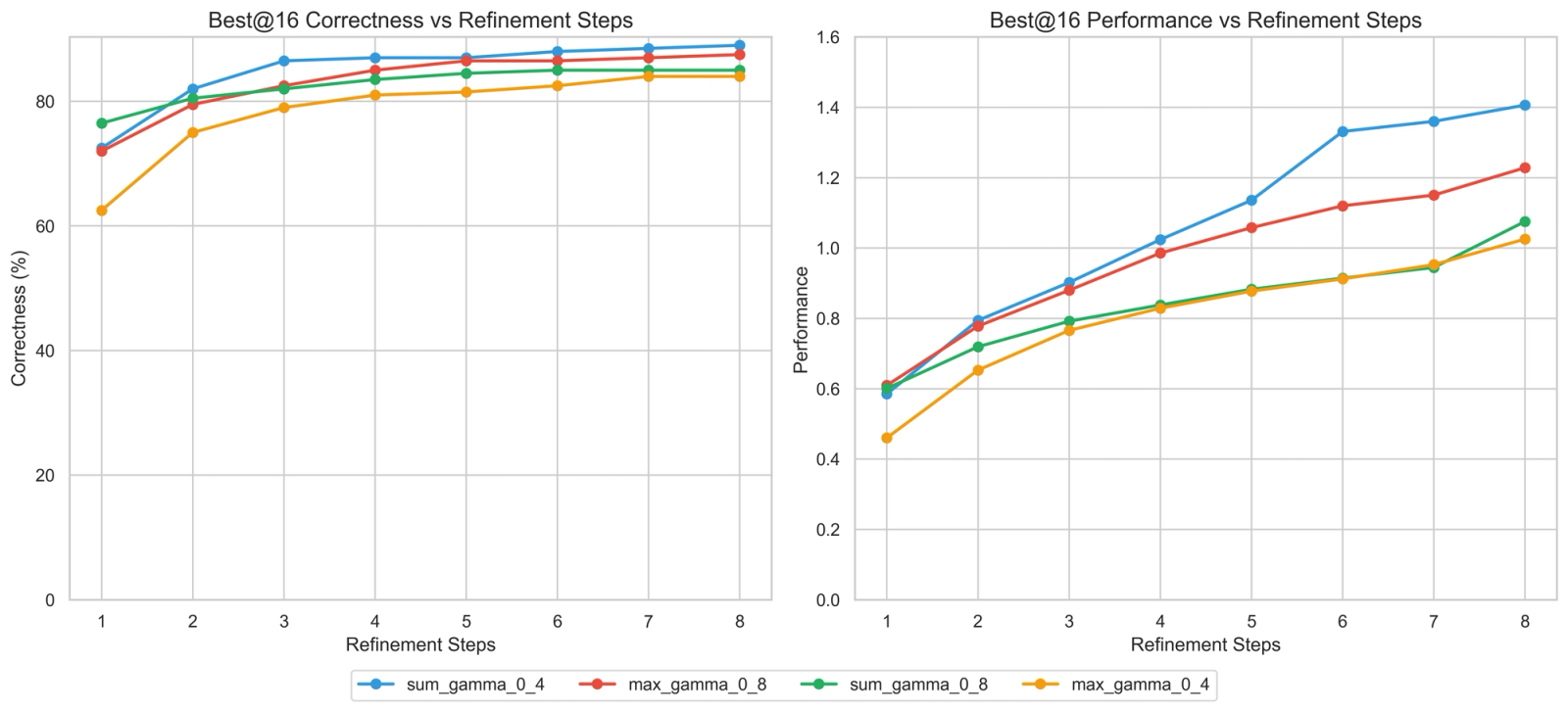
Ablation of reward shaping — Multi Turn Training was done with sum of reward and gamma=0.4 (sum_gamma_0_4).
Parallel Trajectories
We also experimented with quadrupling the number of parallel trajectories from 16 to 64 during training, for a training batch size of 64 * 4 * 8 = 2048. In theory, this makes the advantage estimation less noisy, but we found no significant differences in the evaluated best@16 and avg@16 performance. Moreover, junk starts to appear earlier around step 30 (60 gradient steps).
Data Distribution
Early in the project, we attempted runs with an easy subset of level 1 tasks on DeepSeek-R1-Distill-Qwen-14B. We found that the reward plateaus and the model overfits to a single difficulty level. Moreover, the model only learns a limited set of optimization techniques. Therefore, we think it is important to have a balanced and diverse distribution of difficulty levels in the dataset.
Test-Time Search
During training, search has to be restrained in order to maintain reasonable training times. At test time however, we are free to use more complex test-time techniques to further boost performance.
For our purposes, we use a modified version of beam-search, which works as follows. We first perform 4 serial refinement steps across 16 trajectories, as we do at training time. At the end of this process, we rank the trajectories according to the fastest kernel generated and keep the best 4. We then replicate each of these trajectories 4 times (for a total of 16 trajectories) and repeat the process. Besides being a general method, it boosts the model performance significantly, achieving a mean speedup of 1.56x across the entire dataset.
As expected, we get diminishing returns with increased test-time compute, though average performance still improves even after several hours.
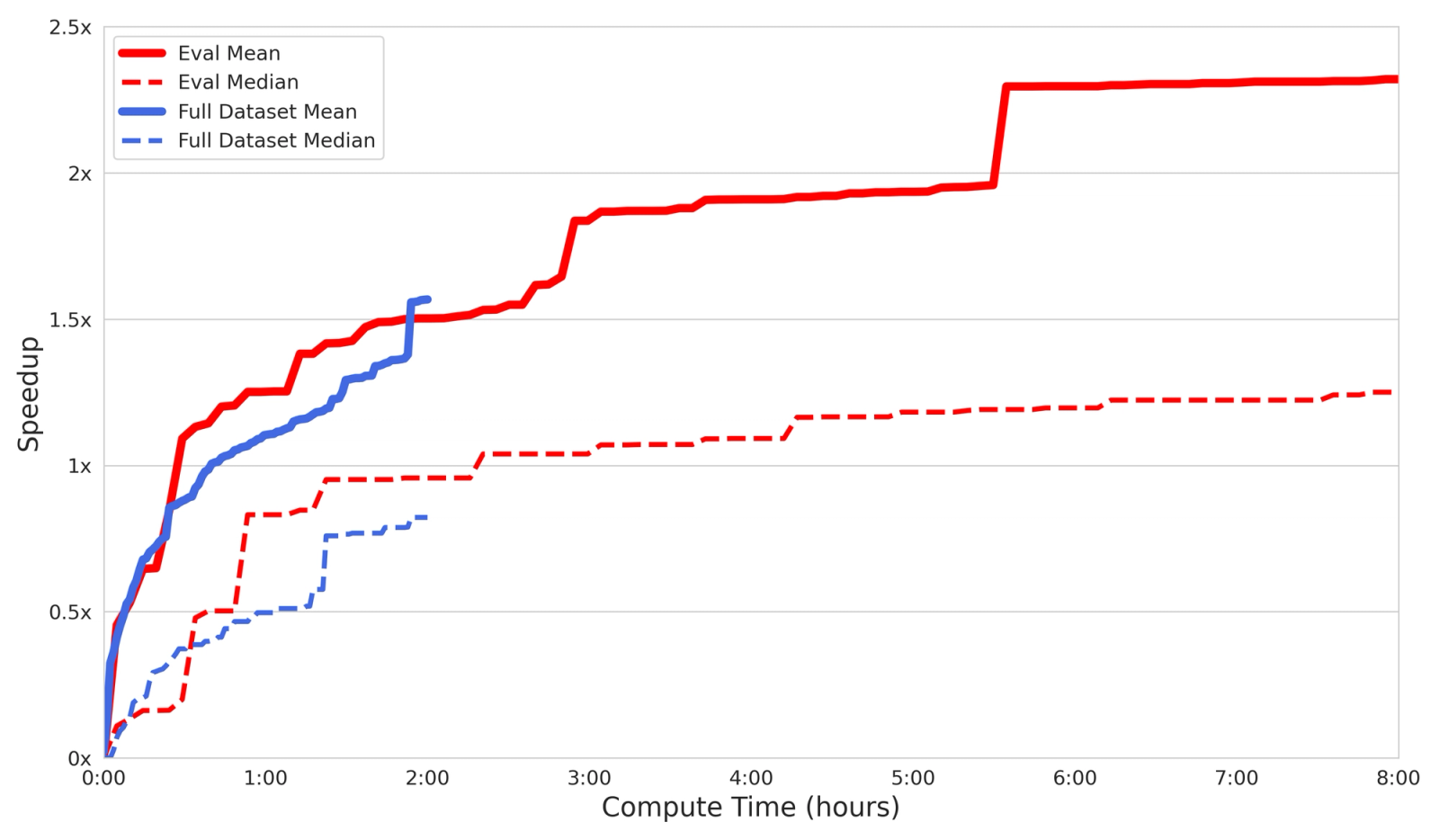
Beam-search test-time inference. Compute Time is measured per-kernel, on a single H200 GPU. Note that it also includes stalling for eval, with the effective inference time accounting for about 45% of the total compute time.
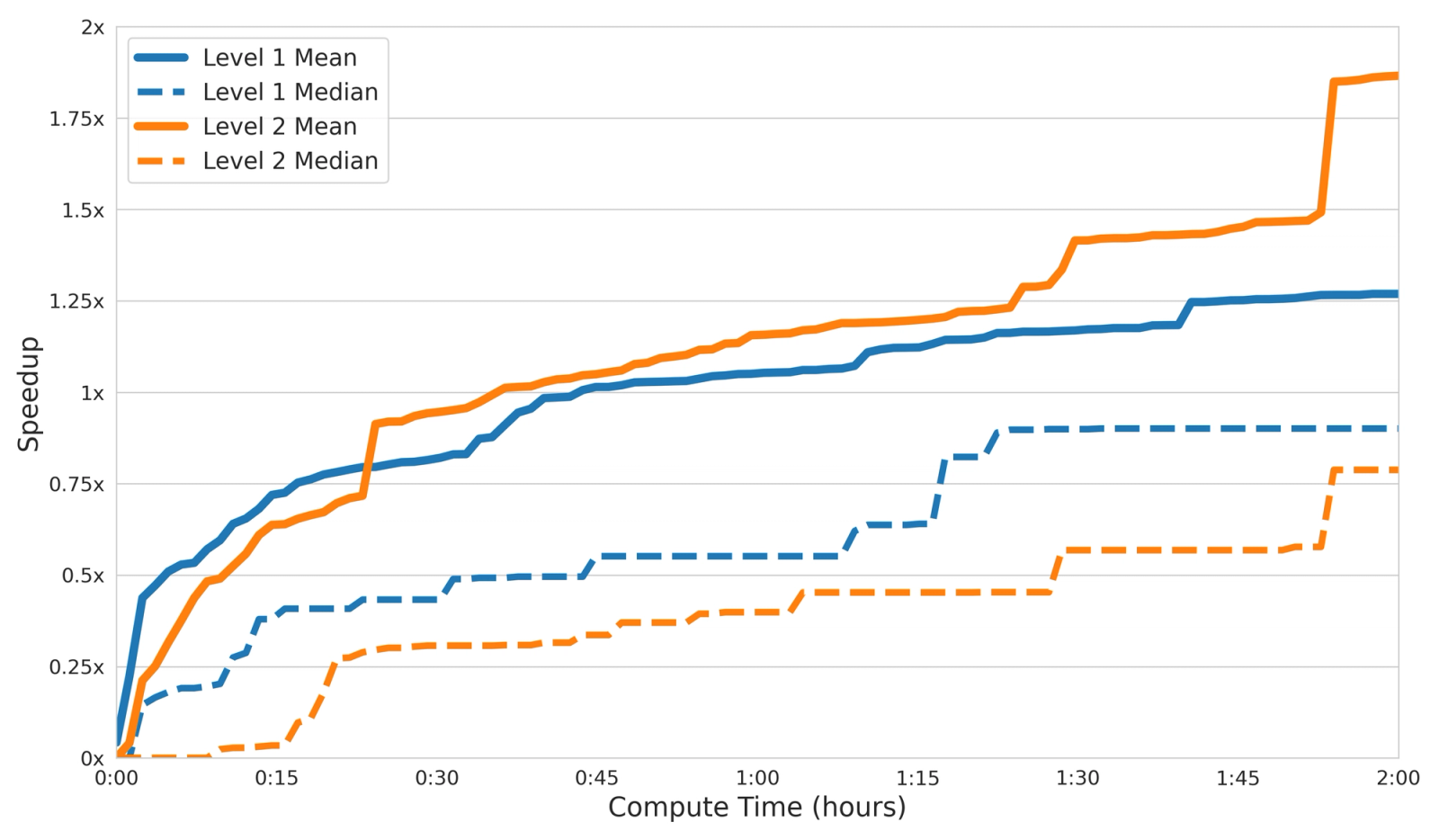
We attempted several different variants of our version of beam search, by modifying number of trajectories, beam width, and number of refinement steps. Interestingly, we observe that settings with a higher median speedup have a lower mean speedup, and vice versa.
We attribute this behavior to each technique having a different position in the Pareto frontier of exploration / exploitation: by being more exploitative, kernels can achieve consistent speedups, though they might miss out on very aggressive optimizations that increase the mean significantly.
Future Work
We believe this work to be only the start of exploring methods to train coding agents. Given more time and compute, here are the things we would like to try:
- Learning a value network and training with PPO. In fact, the baseline estimator is computed per-refinement-step rather than per-prompt
- Integrate more sophisticated search methods, such as beam search, at training time (rather than just parallel + serial)
- Applying multi-turn training method to more general coding environments
Conclusion
In this work we propose a method that generalizes to any multi-turn environment with intermediate rewards. We show that this method achieves better results than single-turn GRPO.
We believe that end-to-end training will be a crucial component of future agents. While hand-crafted multi-LLM workflows can offer short-term gains, they rely heavily on human heuristics and do not scale. In contrast, more general methods let the model freely explore different trajectories (search), and then learn these long-horizon dynamics. Through its interaction with the coding environment, the model produces streams of experiences and continuously adapts through feedback. We hope methods like this to be a first step towards autonomous coding agents.
We have to learn the bitter lesson that building in how we think we think does not work in the long run. The bitter lesson is based on the historical observations that 1) AI researchers have often tried to build knowledge into their agents, 2) this always helps in the short term, and is personally satisfying to the researcher, but 3) in the long run it plateaus and even inhibits further progress, and 4) breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning. Richard Sutton, The Bitter Lesson
HuggingFace: https://huggingface.co/cognition-ai/Kevin-32B
Appendix
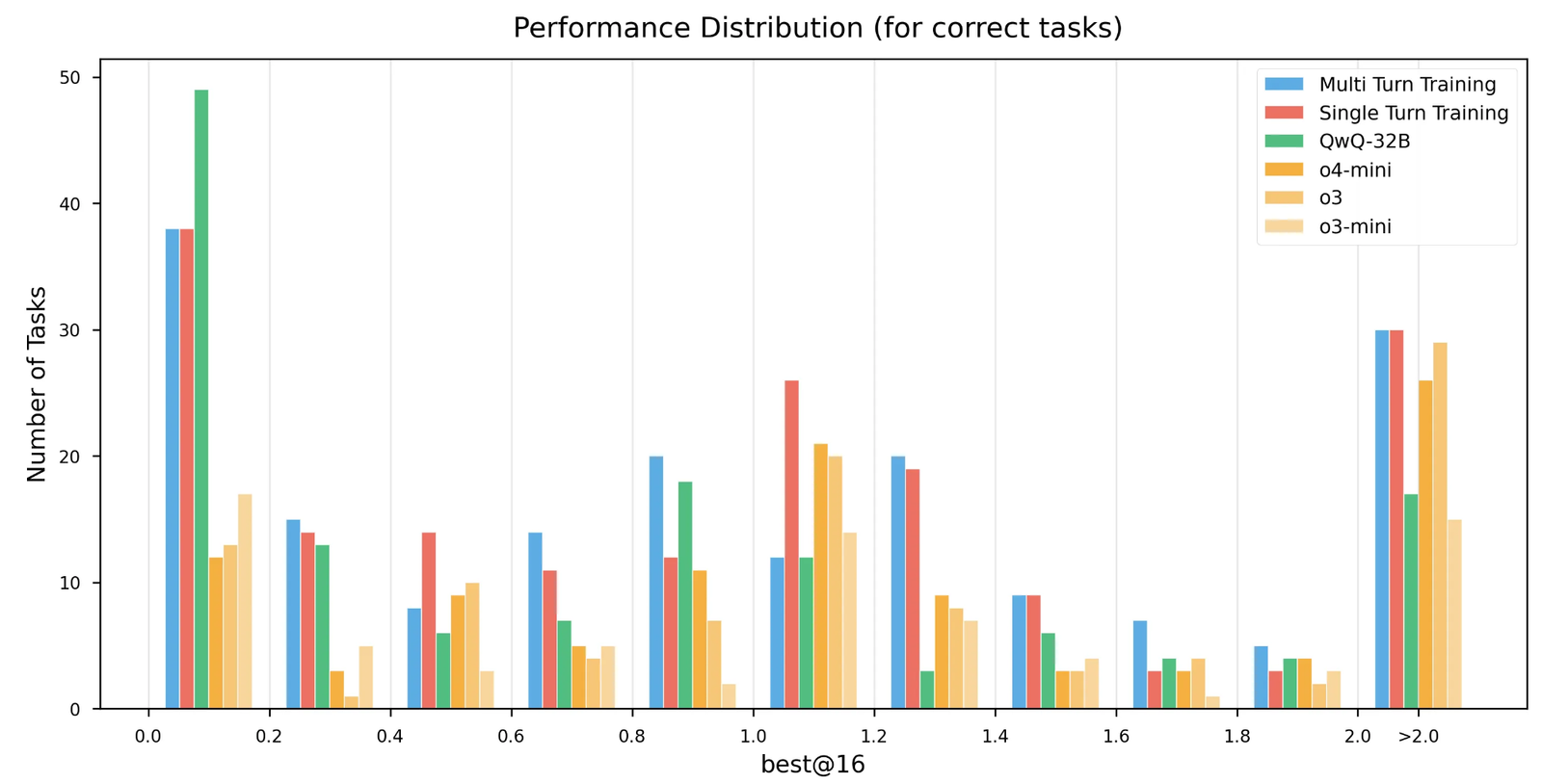
Distribution of performance after 8 refinement steps
Full Sample Kernel
__global__ void layer_norm_kernel(const float* __restrict__ x,
const float* __restrict__ scale,
const float* __restrict__ bias,
float* __restrict__ y,
int N,
int D,
float eps) {
int n = blockIdx.x;
const int tid = threadIdx.x;
const int block_size = 1024;
float sum = 0.0f;
float sum_sq = 0.0f;
for (int d = tid; d < D; d += block_size) {
float x_val = x[n * D + d];
sum += x_val;
sum_sq += x_val * x_val;
}
// Warp-level reduction using shuffle instructions
int warp_id = tid % 32;
int warp_lane = tid / 32;
float warp_sum = sum;
float warp_sum_sq = sum_sq;
for (int delta = 1; delta <= 16; delta <<= 1) {
float other_sum = __shfl_xor_sync(0xFFFFFFFF, warp_sum, delta);
float other_sum_sq = __shfl_xor_sync(0xFFFFFFFF, warp_sum_sq, delta);
warp_sum += other_sum;
warp_sum_sq += other_sum_sq;
}
__shared__ float sum_warp[32];
__shared__ float sum_sq_warp[32];
__shared__ float results[2]; // [mean, inv_std]
if (warp_id == 0) {
sum_warp[warp_lane] = warp_sum;
sum_sq_warp[warp_lane] = warp_sum_sq;
}
__syncthreads();
// Final reduction within the first warp (tid 0-31)
if (tid < 32) {
float my_sum = sum_warp[tid];
float my_sum_sq = sum_sq_warp[tid];
// Reduce within the first warp (32 threads)
for (int s = 16; s >= 1; s >>= 1) {
my_sum += __shfl_xor_sync(0xFFFFFFFF, my_sum, s);
my_sum_sq += __shfl_xor_sync(0xFFFFFFFF, my_sum_sq, s);
}
if (tid == 0) {
float total_sum = my_sum;
float total_sum_sq = my_sum_sq;
float mean = total_sum / D;
float variance = (total_sum_sq / D) - mean * mean;
float inv_std = rsqrtf(variance + eps);
results[0] = mean;
results[1] = inv_std;
}
}
__syncthreads();
float mean = results[0];
float inv_std = results[1];
for (int d = tid; d < D; d += block_size) {
float x_val = x[n * D + d];
float y_val = (x_val - mean) * inv_std;
y_val = y_val * scale[d] + bias[d];
y[n * D + d] = y_val;
}
}Example Prompt
Our prompt is very similar to the KernelBench prompt. Here is an example.
You are given the following architecture:
import torch
import torch.nn as nn
class Model(nn.Module):
"""
Simple model that performs Layer Normalization.
"""
def __init__(self, normalized_shape: tuple):
"""
Initializes the LayerNorm layer.
Args:
normalized_shape (tuple): Shape of the input tensor to be normalized.
"""
super(Model, self).__init__()
self.ln = nn.LayerNorm(normalized_shape=normalized_shape)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Applies Layer Normalization to the input tensor.
Args:
x (torch.Tensor): Input tensor of shape (*, normalized_shape).
Returns:
torch.Tensor: Output tensor with Layer Normalization applied, same shape as input.
"""
return self.ln(x)
Replace pytorch operators in the given architecture with raw CUDA kernels, optimizing for performance on NVIDIA H100 (e.g. shared memory, kernel fusion, warp primitives, vectorization,...). Use torch.utils.cpp_extension.load_inline and name your optimized output architecture ModelNew. You're not allowed to use torch.nn (except for Parameter, containers, and init). The input and output have to be on CUDA device. Your answer must be the complete new architecture (no testing code, no other code): it will be evaluated and you will be given feedback on its correctness and speedup so you can keep iterating, trying to maximize the speedup. After your answer, summarize your changes in a few sentences.Here's an example:
import torch.nn as nn
from torch.utils.cpp_extension import load_inline
# Define the custom CUDA kernel for element-wise addition
elementwise_add_source = """
#include <torch/extension.h>
#include <cuda_runtime.h>
__global__ void elementwise_add_kernel(const float* a, const float* b, float* out, int size) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
out[idx] = a[idx] + b[idx];
}
}
torch::Tensor elementwise_add_cuda(torch::Tensor a, torch::Tensor b) {
auto size = a.numel();
auto out = torch::zeros_like(a);
const int block_size = 256;
const int num_blocks = (size + block_size - 1) / block_size;
elementwise_add_kernel<<<num_blocks, block_size>>>(a.data_ptr<float>(), b.data_ptr<float>(), out.data_ptr<float>(), size);
return out;
}
"""
elementwise_add_cpp_source = (
"torch::Tensor elementwise_add_cuda(torch::Tensor a, torch::Tensor b);"
)
# Compile the inline CUDA code for element-wise addition
elementwise_add = load_inline(
name="elementwise_add",
cpp_sources=elementwise_add_cpp_source,
cuda_sources=elementwise_add_source,
functions=["elementwise_add_cuda"],
verbose=True,
extra_cflags=[""],
extra_ldflags=[""],
)
class ModelNew(nn.Module):
def __init__(self) -> None:
super().__init__()
self.elementwise_add = elementwise_add
def forward(self, a, b):
return self.elementwise_add.elementwise_add_cuda(a, b)Citation
@misc{kevin-multi-turn-rl,
title={Kevin: Multi-Turn RL for Generating CUDA Kernels},
author={Carlo Baronio and Pietro Marsella and Ben Pan and Simon Guo and Silas Alberti},
year={2025},
eprint={2507.11948},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2507.11948},
}




