Introducing SWE-1.5: Our Fast Agent Model
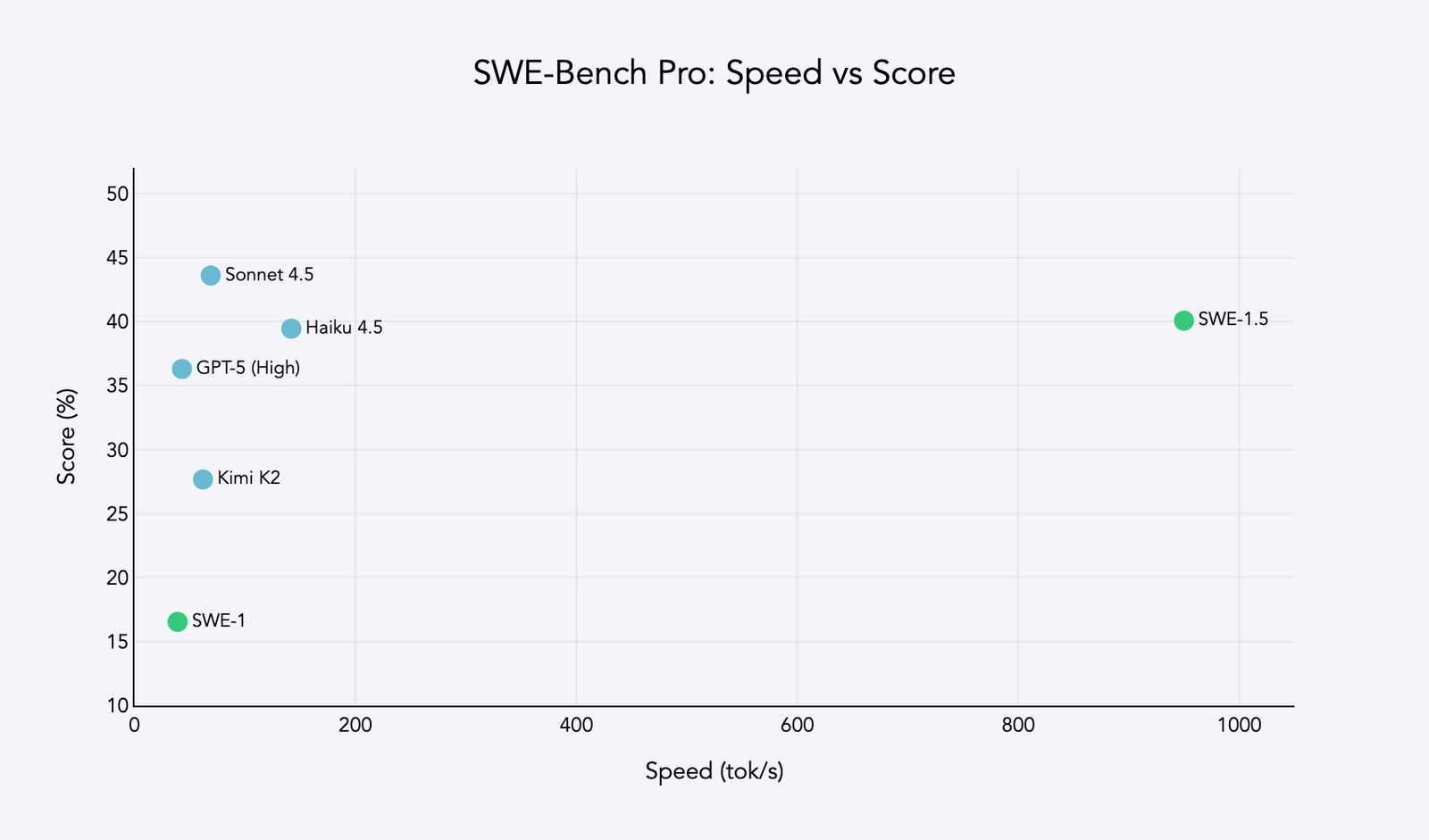
Today we’re releasing SWE-1.5, the latest in our family of models optimized for software engineering. It is a frontier-size model with hundreds of billions of parameters that achieves near-SOTA coding performance. It also sets a new standard for speed: we partnered with Cerebras to serve it at up to 950 tok/s – 6x faster than Haiku 4.5 and 13x faster than Sonnet 4.5. SWE-1.5 is now available in Windsurf!
Motivation
Developers shouldn’t have to choose between an AI that thinks fast and one that thinks well. Yet, this has been a seemingly inescapable tradeoff in AI coding so far. We’ve been chipping away at this constraint — on October 16 we released SWE-grep, an agentic model trained for rapid context engineering without sacrificing performance. Now, SWE-1.5 reimagines the entire stack — model, inference, and agent harness — as a unified system optimized for both speed and intelligence.
The Agent-Model Interface
Our goal as an agent lab is not to train a model in isolation, but to build a complete agent. Often-overlooked components are the agent harness, the inference provider, and the end-to-end user experience. As a result, the development process for SWE 1.5 involved:
- End-to-end reinforcement learning (RL) on real task environments using our custom Cascade agent harness on top of a leading open-source base model.
- Continuous iteration on the model training, harness improvements, tools, and prompt engineering.
- Rewriting core tools and systems from scratch when needed for better speed and accuracy (lots of things become bottlenecks when a model runs 10x faster!). This is an area where we plan to continue making progress. Improvements here also contribute to the performance of all other models in Windsurf.
- Heavy reliance on real-world internal dogfooding to drive tuning decisions, which allowed us to tune the agent and model on user experience in a way that general-purpose reward functions could not.
- Deploying multiple beta versions of the model (under the "Falcon Alpha" name) and monitoring performance metrics.
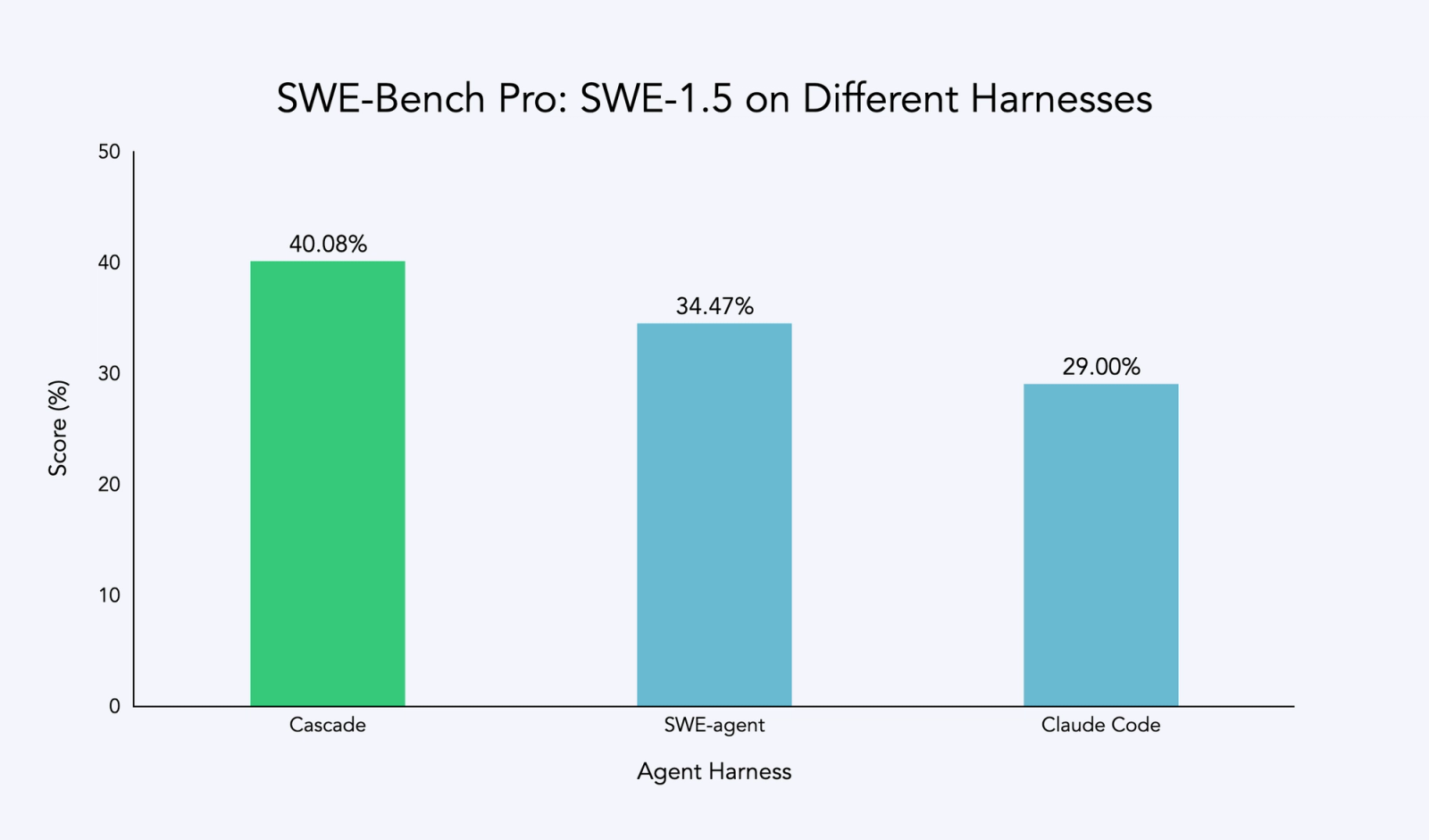
After tuning, we observed a noticeable performance improvement over evaluations done in alternative harnesses. Note that this is not a reflection of the capability of the harnesses themselves: models tuned for the other harnesses could perform just as well if not better (e.g. Sonnet in Claude Code). A notable factor in the lower scores was a greater incidence of tool call failures.
Picking a coding agent isn’t just about the model itself. The surrounding orchestration also has an outsized impact on how the model performs. Working on Devin, we often wished we could co-develop the model and the harness, and with this release we are finally able to do just that.
RL Coding Environments
We believe that the quality of the coding environments in RL tasks is the most important factor for downstream model performance. We’ve observed the following issues with commonly used coding environments:
- Narrow task distribution: Many labs try to hillclimb SWE-Bench which has a very narrow set of repositories and task types.
- Ignoring soft factors: When using exclusively verifiable correctness rewards like unit tests, the models aren’t incentivized to write high-quality code. This results in what is widely known as “AI slop”: code that is overly verbose, uses excessive try-catch blocks and other anti-patterns.
To address these issues, we manually created a dataset that aims to mirror the wide distribution of real-world tasks & languages we see across Devin and Windsurf. We invested heavily into creating our own evals, based on our learnings from our work on Devin and the Junior-Dev Benchmark.
We also worked with a hand-selected team of top senior engineers, open-source maintainers, and engineering leaders to design high-fidelity coding environments. We have three grading mechanisms in our environments:
- Classical tests (e.g. unit tests, integration tests) for reliably validating correctness
- Rubrics for code quality and approach
- Agentic grading that leverages a browser-use agent to test end-to-end functionality of product features
These grading mechanisms usually complement each other well and many environments use a combination of all three at once. To ensure our environments are robust to reward hacking, we developed a process we call reward hardening, where human experts try to find ways to circumvent the graders. Early results show that after multiple rounds of hardening we can discover many gaps in classical tests and significantly reduce false positive rates, though this requires further research.
SWE-1.5 represents our first attempt at leveraging these environments to improve coding capabilities. We’re only at the beginning of scaling up the production of these coding environments, so SWE-1.5 is trained at a relatively small scale. We expect to see much stronger effects, especially on soft factors like code quality, in future model generations.
Training & Infrastructure
SWE-1.5 is trained on our state-of-the-art cluster of thousands of GB200 NVL72 chips. We believe SWE-1.5 may be the first public production model trained on the new GB200 generation. We were one of the first companies to receive access to the new hardware in early June, when the firmware was still immature and the open-source ecosystem was non-existent. The first few months on the new chips were a journey: it required building more robust health checking, fault-tolerant training, and learning how to leverage rack-scale NVLink.
After careful evals and ablations, we selected a strong open-source model as the base for our post-training. We use reinforcement learning (RL) on the Cascade agent harness in our high-quality coding environments to optimize the model for our product and task distribution. Our vision is to co-optimize models and harness: we repeatedly dogfooded the model, noticed issues with the harness, made adjustments to tools and prompts, and then re-trained the model on the updated harness. For training stability on long multi-turn trajectories we used a variant of unbiased policy gradient (as described in the SWE-grep blogpost).
Our RL rollouts require high-fidelity environments with code execution and even web browsing. To achieve this, we leveraged our VM hypervisor otterlink that allows us to scale Devin to tens of thousands of concurrent machines (learn more about blockdiff). This enabled us to smoothly support very high concurrency and ensure the training environment is aligned with our Devin production environments.
Public Evals
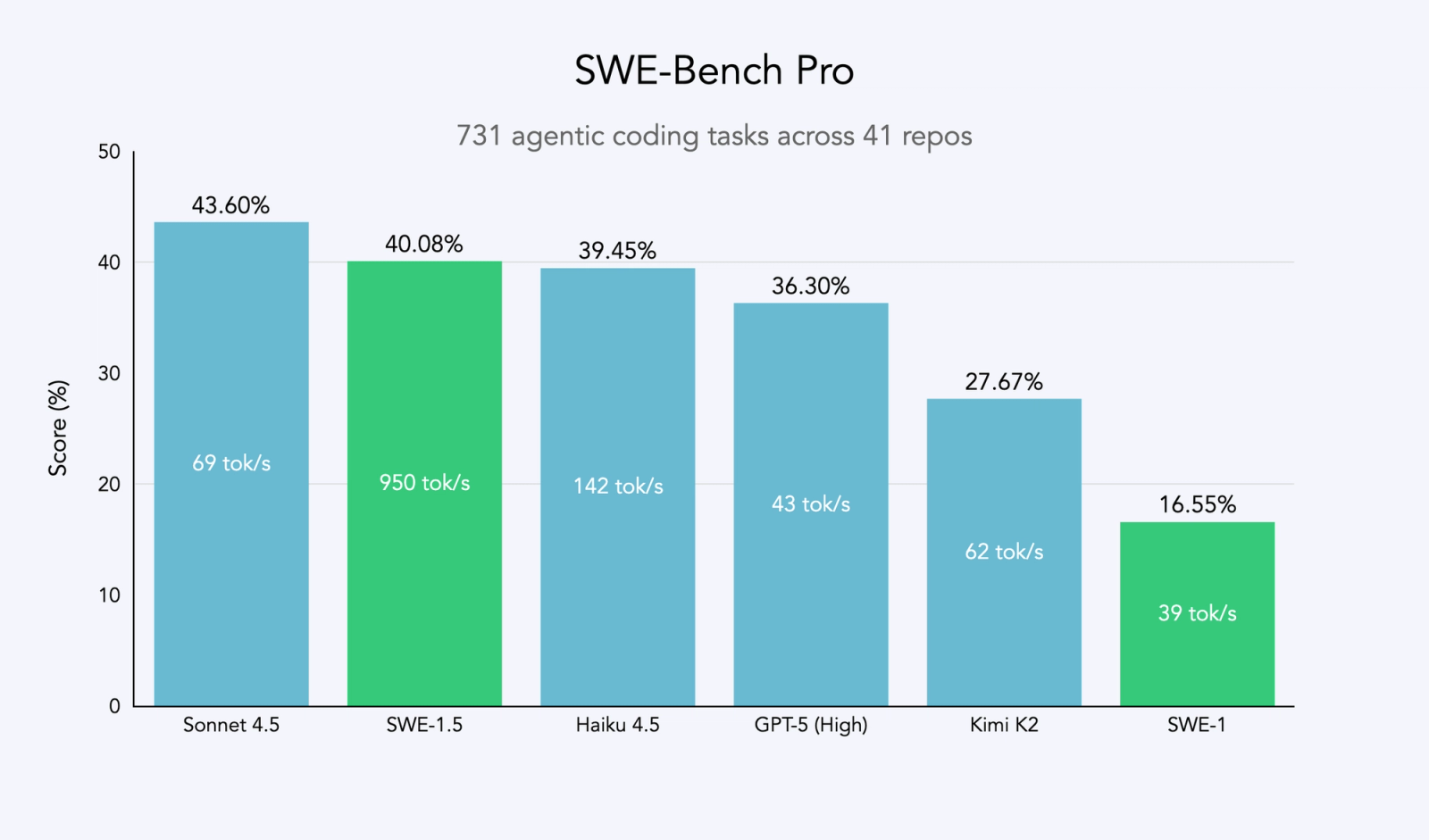
Performance on coding benchmarks is often not representative of the real-world experience of using an agent, which is why we stopped reporting SWE-Bench numbers in 2024. Nonetheless, it is a good common baseline for comparing the ability of a model. We used the more advanced SWE-Bench Pro benchmark from Scale AI, a dataset of difficult tasks on diverse codebases. Here SWE-1.5 achieved near-frontier performance, while completing tasks in a fraction of the time.
Most importantly, many of our engineers now use SWE-1.5 as their daily driver. Some popular use cases include:
- Deeply exploring/understanding large codebases (SWE-1.5 also now powers our beta Codemaps feature)
- Building end-to-end full stack apps
- Easily editing configurations without needing to memorize field names
One of our engineers noted that while existing agents would correctly edit a Kubernetes manifest, this task would take around 20 seconds. Now, such tasks are completed in under 5 seconds, within the “flow window” of the semi-async valley of death.
Optimizing for Speed
Our goal for SWE-1.5 was to create the fastest coding agent experience available. To do this, we worked with Cerebras, the fastest inference provider, to deploy and optimize SWE-1.5. This included training an optimized draft model for faster speculative decoding, and building a custom request priority system for smoother end-to-end agent sessions. With a model running at up to 950 tok/s, previously negligible system delays emerged as dominant bottlenecks, forcing us to revisit several key parts of the Windsurf agent implementation. We rewrote critical components including lint checking and command execution pipelines, which reduced overhead per step by up to 2s. This is an effort we plan to continue investing in.
What’s Next
SWE-1.5 proves you don't have to choose between speed and intelligence. By co-designing the model, inference system, and agent harness as one unified system, we've achieved frontier-level performance at 13x the speed of Sonnet 4.5. Similar to SWE-1, SWE-1.5 was the product of a small and incredibly focused team, and leveraged our strengths as an agent lab that combines product, research, and infrastructure to build the world’s best software engineering agents. SWE-1.5 is a major step forward, but we're excited to keep pushing the boundaries of what’s possible in upcoming iterations.
You can try out SWE-1.5 in Windsurf starting today.








