An Early Preview of SWE-1.6 and Research Update
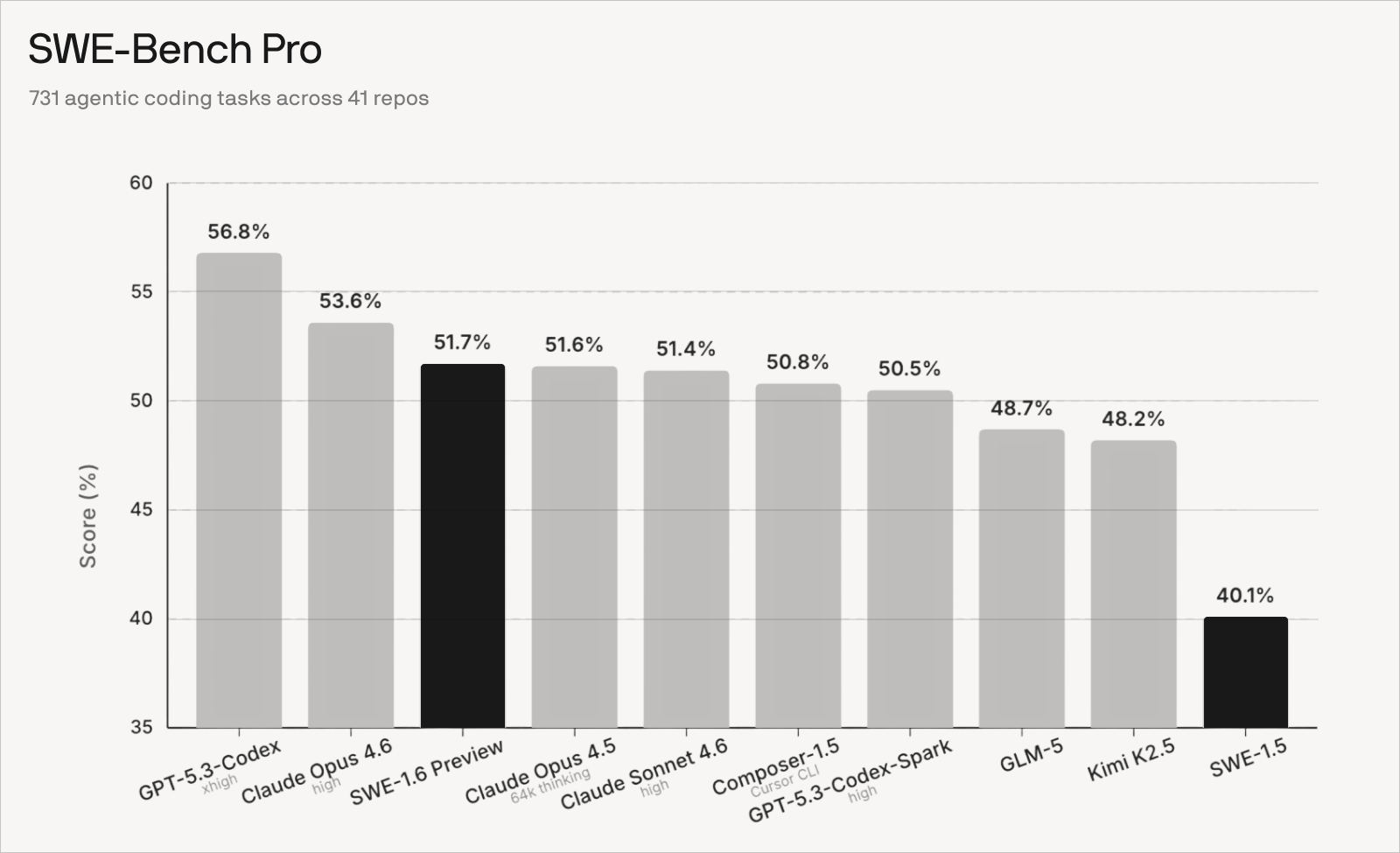
We are sharing an early preview of our ongoing SWE-1.6 training run. Since training SWE 1.5, we have refined our RL recipe and scaled our infrastructure to unlock two orders of magnitude more compute. Our next model SWE-1.6 is post-trained on the same pre-trained model as SWE-1.5 and runs equally as fast at 950 tok/s. The current checkpoint achieves an 11% higher score than SWE-1.5 on SWE-Bench Pro.
Training this model has taught us a lot about how RL can affect the “user experience” of a model. For example, our current checkpoint exhibits behaviors like overthinking and excessive self-verification. This is an active area of research for us - we believe Model UX is an important axis that isn’t captured by benchmarks like SWE-Bench Pro.
We are rolling out early access to this model to a small subset of users to collect feedback for tuning model behavior. Our goal for the preview period is to fix rough edges and further push intelligence as we continue training the model!
Evaluation Details
We chose to evaluate SWE-1.6 on SWE-Bench Pro following OpenAI’s recommendation as the spiritual successor of SWE-Bench Verified. Running bug-free and reproducible evaluations for agents requires care. We manually read hundreds of trajectories and cross-checked against Scale-reported SWE-Bench Pro trajectories when applicable. Some examples of subtle issues we resolved include: dependency issues in agent and grading environment setup, inconsistent handling of timeouts across harnesses, edge cases in patch collection and application, and out-of-memory during grading. We also double checked there is no overlap in repositories between training tasks & SWE-Bench Pro tasks.
For Claude Opus 4.6 and Sonnet 4.6 we used high reasoning effort and reported the best result from runs across three harnesses: Claude Code, Cascade (Windsurf), and Devin. Anthropic did not report SWE-Bench Pro results for Opus 4.6 and Sonnet 4.6. For Claude Opus 4.5 we used Anthropic’s officially reported results for the 64k thinking setting. For GPT-5.3-Codex and GPT-5.3-Codex-Spark we used OpenAI’s reported results (Codex, Codex Spark). We attempted to replicate GPT-5.3-Codex results on three harnesses (Codex CLI, Cascade, and Devin) but obtained a slightly worse measurement (54.0% best). For GLM-5 and Kimi K2.5 we report the best result of two harnesses (Cascade and Devin). We ran Composer-1.5 under the Cursor CLI and did multiple iterations of spot checking and re-runs towards ensuring that we report a fair measurement. For SWE-1.6-Preview and SWE-1.5 we evaluated on the Cascade harness with the same system prompt and settings as in the Windsurf product.
Scaling RL
Since our early attempts at agentic RL, including Kevin-32B and SWE-grep, we have continued to refine our algorithm for stable training. We have significantly scaled the number of RL environments while further improving data quality. As a consequence, we observe continued improvements as we train for more steps.
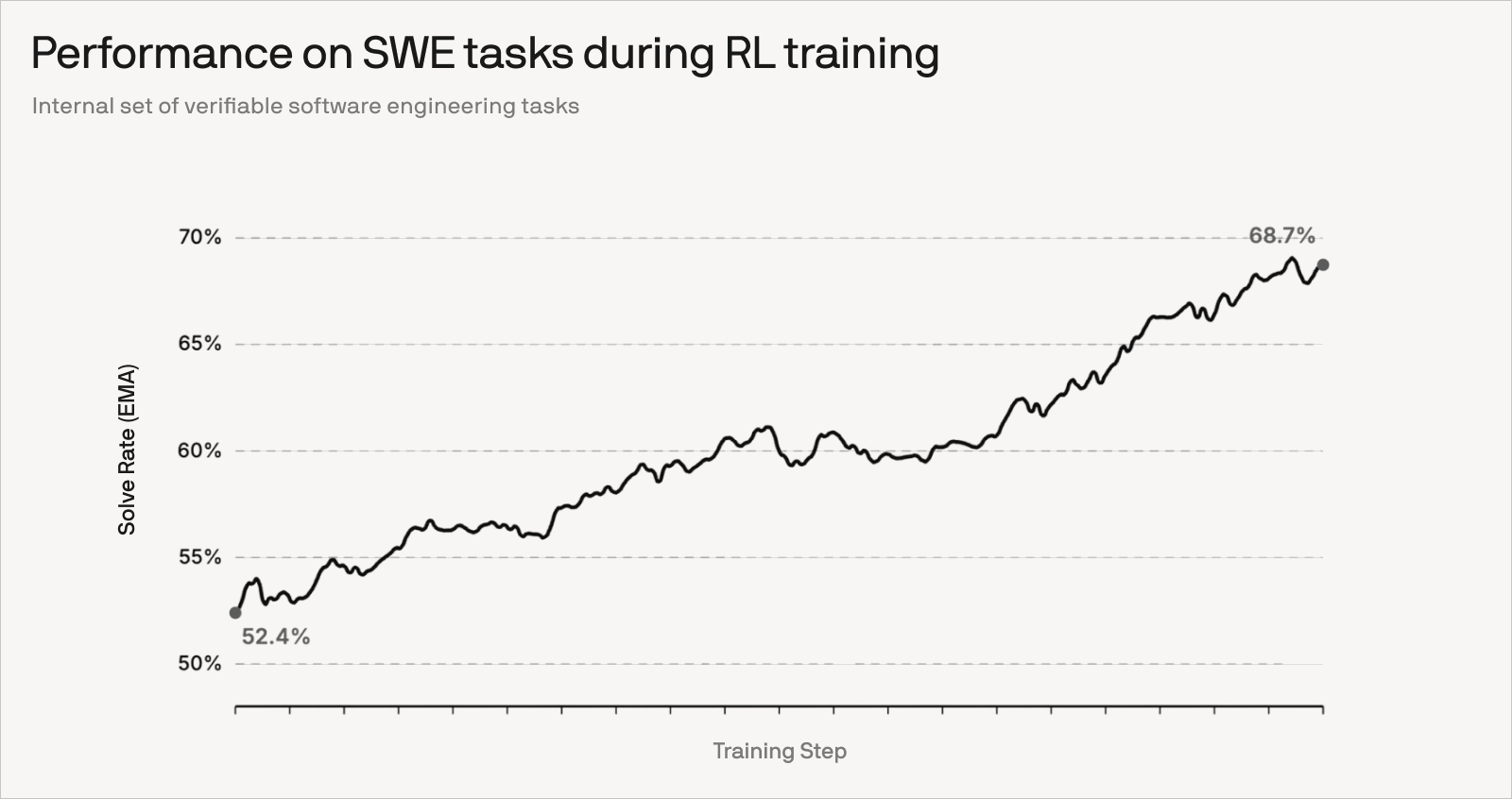
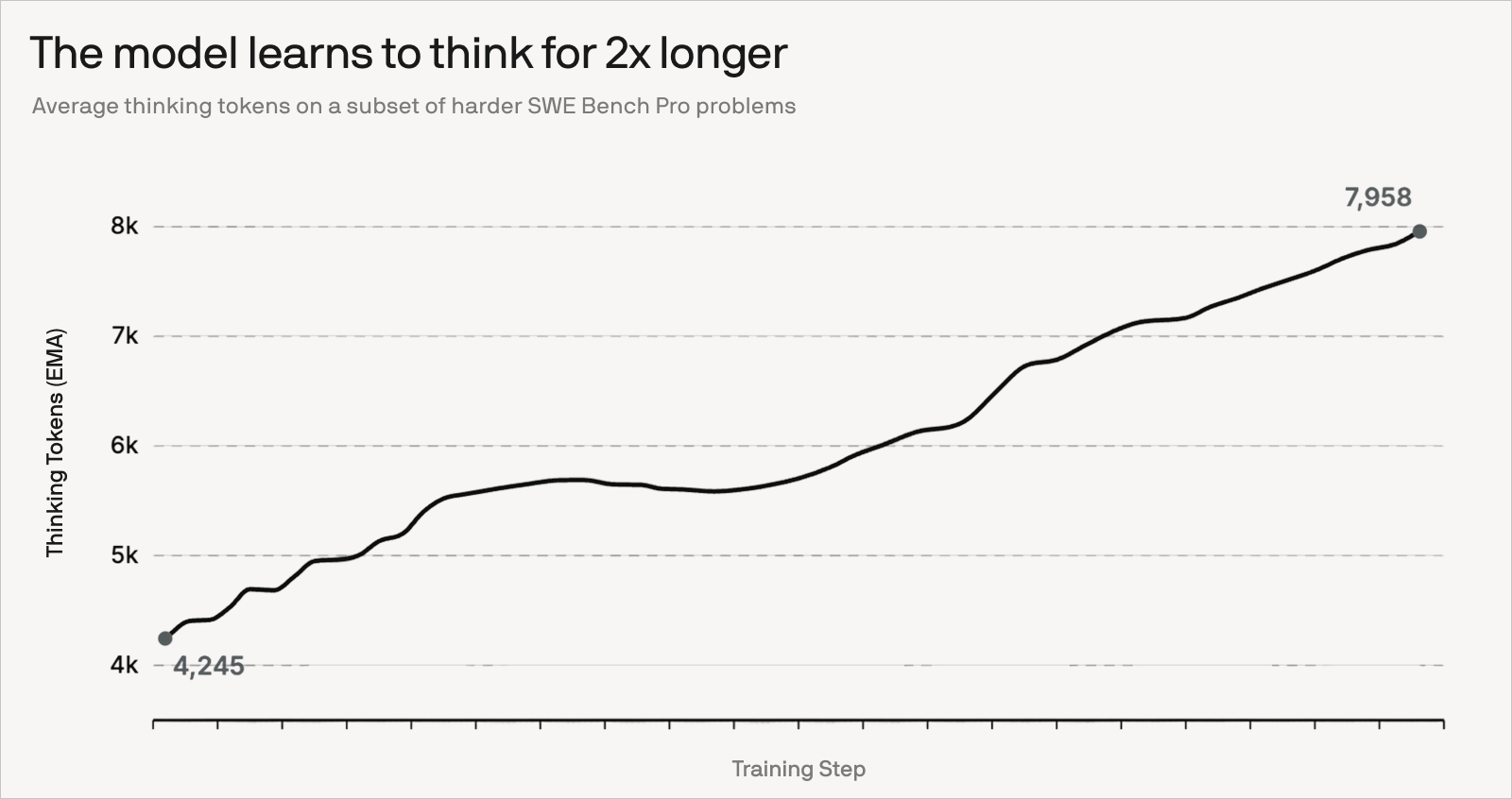
It has been fun to observe the model learning to think harder and iterate for more turns on hard SWE-Bench Pro problems. On the flip side, we observe overthinking and excessive self-verification in our own dogfooding. Figuring out the right balance between interactivity and long-horizon thinking is an active area of research.
How we made our training 6x faster
Our philosophy is: first get it working, then make it fast. Since SWE-1.5, through a variety of improvements, our training stack is more stable, and training steps for SWE-1.6 now run 6x faster than they did 3 months ago (normalizing for batch size).
Rollouts on long-horizon software engineering tasks often require tens or hundreds of turns interacting with the environment. With this profile in mind, we’ve made several choices that improved our rollout throughput.
First, we’ve optimized our inference configurations, in particular using lower precision. However, this introduces issues like high mismatch between training and inference logprobs. We’ve made algorithmic improvements that enabled us to use rollouts in precisions as low as NVFP4, which is a numeric format optimized for Blackwell chips, and achieved 2-3x higher throughput than with BF16 or FP8.
As multi-turn rollouts are made up of serial requests that share prefixes, we tag each rollout with a corresponding DP rank ID and route that rollout’s requests to the specified rank, maximizing KV cache hit rate and maintaining balanced workloads across DP ranks.
Finally, we’ve significantly improved the stability and performance of our training infrastructure. SWE-1.6 was trained on thousands of GB200 NVL72 chips, requiring attention to stable networking. Moreover, we were able to accelerate our training by 1.5x using NVIDIA’s Multi-Node NVLink.
GPUs Allocation and Staleness
In async RL we can think of the system as a two-stage pipeline:
- An inference/rollout stage that generates samples (trajectories).
- A training stage that consumes those samples and runs one optimizer step whenever B samples are ready.
In steady state, rollouts and training overlap, and the wall-clock time per optimizer step is set by whichever stage is slower. If inference produces samples faster than training can consume them, the sample queue grows without bound. If training is faster, then the trainer sits idle waiting for samples. A good first guess for the optimal GPU split is therefore the one that balances the two stages.
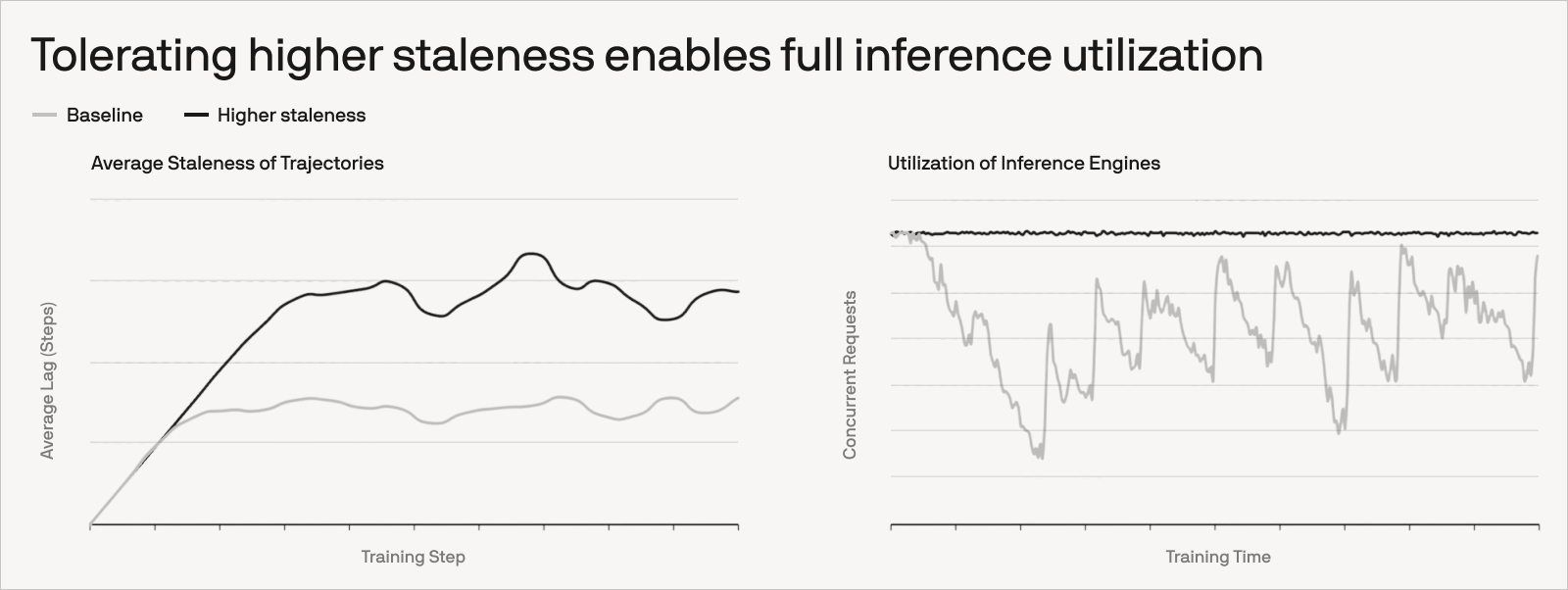
Thanks to our algorithmic improvements, we can neglect staleness (the number of optimizer steps between when a rollout starts and when its samples are consumed by training) when choosing the GPU split. We also ignore the time to refresh and broadcast the updated weights to inference engines, assuming it’s negligible compared to rollout generation and the training step (or amortized asynchronously).
Given these assumptions, we can use the following simple model to produce a first guess for the inference/training allocation. Suppose that:
- We have N total GPUs, split into nᵢ inference GPUs and nₜ training GPUs,
- Each optimizer step consumes B samples,
- The inference engines sustain s_roll output tokens/sec/GPU at saturation (measured end-to-end, including prefill),
- r denotes the output-to-input token ratio,
- L_out is the average number of output tokens per trajectory,
- The trainer runs at s_train tokens/sec/GPU for the update workload.
One practical detail is that we parameterize inference cost using (1) the measured output tokens/sec on the inference engines, and (2) the average output/input token ratio. This works well in our setup because we do not re-prefill the entire history at each turn, so the “input tokens” we pay are primarily the newly appended prompt tokens. We enable this by “sticking” each trajectory to an inference engine, which can then keep the trajectory’s KV cache resident across turns. As a result, the end-to-end measured output throughput (s_roll) already reflects the real prefill+decode cost, and r = in/out can be interpreted as the ratio of newly-prefilled tokens to generated tokens along the rollout.
From r, the number of total tokens per trajectory is L_tot = L_out + L_in = L_out⋅(1+r). Rollouts for a turn generate B⋅L_out output tokens in total. With nᵢ inference GPUs producing output at total rate nᵢ⋅s_roll:
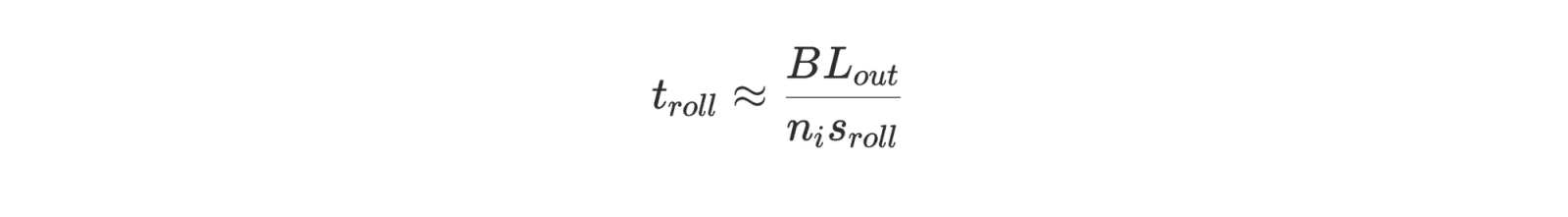
Training does work proportional to B⋅L_tot tokens. With nₜ GPUs at s_train effective tokens/sec/GPU:

Because rollout generation and training overlap, the steady-state step time is approximately t_step ≈ max(t_roll, t_train). To minimize step time, we want t_roll ≈ t_train. Setting them equal cancels B and L_out, and we can solve for the training allocation:
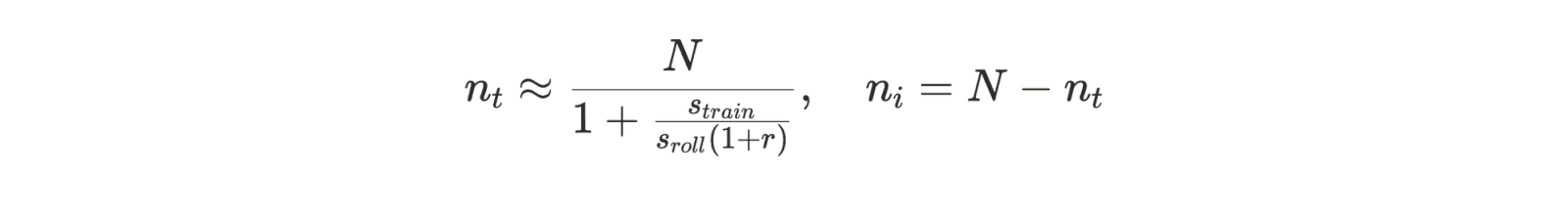
In our system each inference rank runs an optimal fixed concurrency c (the number of in-flight rollouts per engine). Each optimizer step consumes B samples, so a natural equilibrium estimate for step-based staleness is ≈ c⋅n_i/B. Plugging in the equilibrium allocation for nᵢ yields an explicit expression in terms of the same measured throughputs.
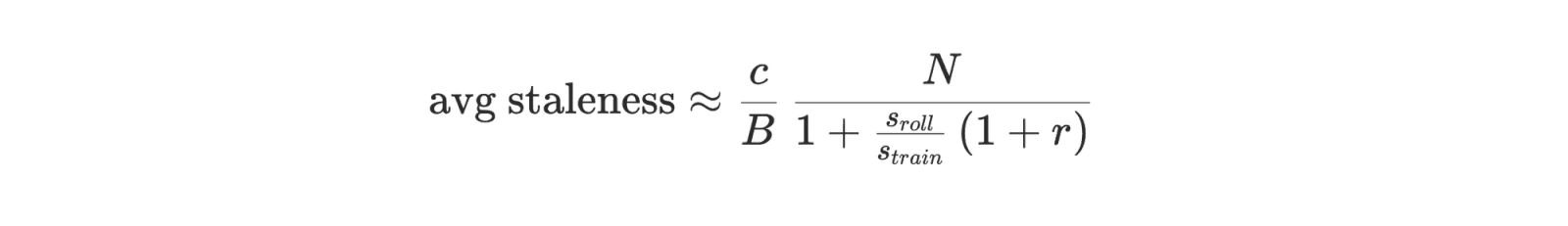
The missing axis: Model UX
The industry has moved to benchmarks like SWE-Bench Pro, which is more difficult, less contaminated, and more representative of ability to solve longer horizon tasks compared to previous SWE benchmarks. Through large-scale RL, SWE-1.6 has improved significantly on that benchmark over SWE-1.5. Qualitatively, we’ve noticed that SWE-1.6 thinks for longer and takes more turns, especially for harder queries.
However, one axis these benchmarks don’t measure is “Model UX”. We’ve previously discussed some of these ideas in the “Semi-Async Valley of Death” in our SWE-grep and SWE-1.5 blog post. Back then, we optimized for the interactive side of the software engineering experience, focusing on speed.
Windsurf Arena mode was a first step towards this, by measuring blind subjective preference on real coding tasks. SWE-1.5 performed better than we expected here, which we largely attribute to its speed.
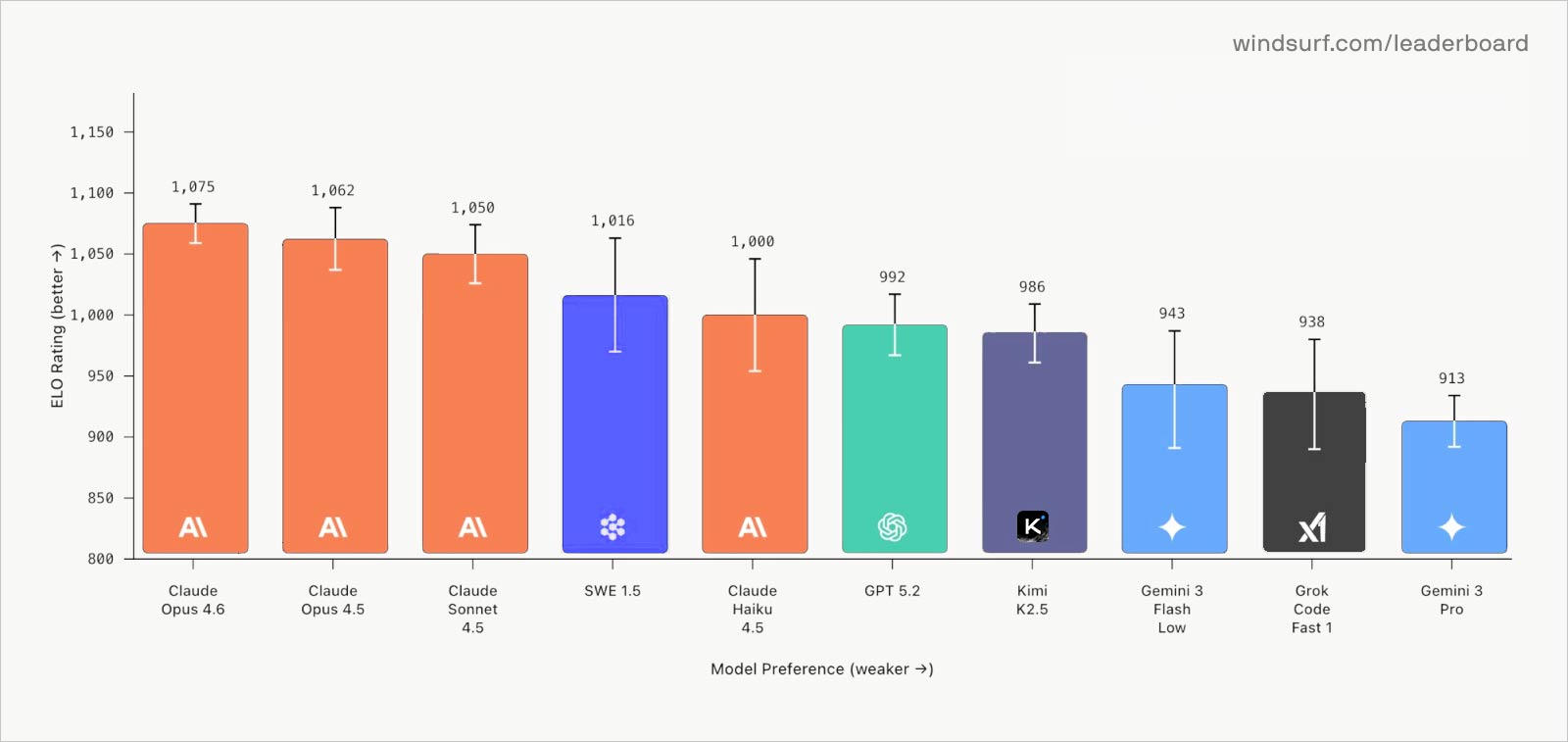
However, this ranking misses some critical details. Now that background agents are attaining wider adoption, we believe the following aspects of model UX will matter even more:
- Ability to infer intent from incomplete context
- Visibility of chain of thought, commands being run, or todo list
- Tool call efficiency and non-invasiveness
- Adaptive thinking
- Instruction following over multiple turns
We notice that large-scale reinforcement learning can improve the model’s intelligence and incentivize it to think for longer, but can come at a tradeoff by introducing undesirable behaviors.
For example, we noticed that SWE-1.6 Preview learns to use bash commands for search instead of pre-defined tools because terminal commands are more expressive and allow it to solve the task faster. But complex commands give less visibility into the model’s problem solving trajectory. Excessive use of commands is also annoying for the user, who has to manually approve each command every 10-20 seconds or so over a very long horizon, when they might otherwise have switched to a different task already.
We were able to address many undesirable behaviors from SWE-1.5. Now our model:
- Avoids writing unnecessary unit tests and documentation
- Uses todo lists to track progress for long-running tasks
- Adopts a professional tone and keeps answers concise and clear
- Explores the codebase, gathers context, and reasons before jumping into coding
However, we think that large-scale RL has introduced undesirable behaviors:
- Overthinking / reasoning in loops / excessive self-verification
- High number of turns
- Executing long-running commands synchronously instead of in the background
- Using sequential tool calls when they could’ve been run in parallel
We aim to improve these behaviors in our next training runs, and we’re excited to do more research around ways to improve UX in general through model training.
Extra credit: We want to highlight some members of our contractor team who have made outsized contributions to data & tooling: Claudio Costa, Martin McKeaveney, Lance Fuchia, Tomer Nosrati, Merlijn Vos.







