How Devin Is Modernizing COBOL at Fortune 500 Companies
The pressure to modernize COBOL has never been greater. Forty-seven percent of organizations cannot fill their COBOL roles and 92% of COBOL developers plan on retiring by 2030. As a result, over the past eight months, several Fortune 500 companies have staffed Devin on COBOL project — documenting millions of lines of code, migrating a customs workflow from COBOL to AWS Lambda, and refactoring tax ID logic across hundreds of programs.
To understand how Devin succeeded where most agents don't, it's worth first understanding why COBOL is so difficult for agents — and what it takes to overcome those challenges.
Why COBOL is so Difficult for Agents
Business Critical Data Is Difficult to Trace
In modern languages, tracking a customer's tax ID is straightforward: you create a TaxId variable — a named concept that carries its meaning everywhere it goes. COBOL doesn't work this way. Data moves between programs through copybooks — flat record layouts that define blocks of memory at fixed positions. There are no types, no schemas, and no enforced naming conventions. A field at a given position could be a tax ID, a timestamp, or a control number — the language provides no way to distinguish them semantically.
This becomes especially problematic when data crosses program boundaries. When Program A writes a record to a file, Program B reads it by defining its own layout for that same block of memory. Each program's developer chose their own field names — and because there's no shared schema, nothing connects them except position in memory:

CUST-TAX-NUM and WS-FIELD-01 are the same value — but nothing in the language says so. The implicit dependency between them is invisible. Multiply this across thousands of programs written over decades by different developers, and the same value might exist under dozens of names, connected only by position in memory.
Any change to business critical data requires tracing every program it has touched. At each program boundary, an agent must verify that the same memory offset carries the same value — and a single misidentification makes every subsequent change incorrect.
LLMs Do Not Natively Understand COBOL
Another challenge is that models have been trained on almost no COBOL. Virtually all COBOL lives on mainframes and has never been shared publicly, so LLMs lack the pattern recognition that makes them effective with modern languages.
A retiring COBOL expert can glance at a field name like WS-FIELD-01 and immediately know it's a tax ID. That intuition comes from 30 years of exposure to naming conventions, company-specific patterns, and actually writing COBOL. Models are starting from scratch.
These first two problems compound each other. Tracing business-critical data across thousands of programs requires recognizing what that data actually is — and a model that lacks the pattern recognition to do that reliably makes an already difficult problem significantly harder.
Broken Agent Feedback Loop
The most critical problem is that COBOL breaks the feedback loop that makes agents effective. Because COBOL is designed to run on mainframes, an agent's virtual machine (VM) cannot execute it.
Normally, an agent writes code, runs it, checks the output, and iterates. That loop is what makes agents powerful. But COBOL systems run on mainframes with tightly coupled infrastructure (e.g. job control systems, middleware, legacy databases, and proprietary file systems) none of which exist in a Linux environment.
All leading coding agents run on Linux-based VMs, which means they can read COBOL source code but cannot run or test it. The core mechanism that drives agent performance — fast, autonomous iteration — is fundamentally broken.
What It Takes to Modernize COBOL With Agents
As you can see, this is incredibly difficult to get right — so difficult that 68% of COBOL modernization efforts fail. But agents can still help. We realized that success with COBOL requires two things:
- The agent needs a comprehensive, system-wide map of the codebase before it acts.
Due to the difficulty of tracing COBOL data, it is critical for agents to map the entire codebase before it acts: tracing every call chain, following data across every program boundary, and resolving what each field actually represents across the full system. - For any work that requires running COBOL, the agent needs to restore its feedback loop.
Documentation only requires an agent to read COBOL — the feedback loop problem doesn't apply. But for all other categories of COBOL work, the ability to run and verify is critical. Whether an agent can do that depends on the type of workload.
Batch workloads — which make up 30% to 50% of COBOL migrations — are scheduled, offline processes like reporting and settlements. They take structured inputs and produce deterministic outputs. Because the expected output is known in advance, the agent can recreate the logic in a modern language on its own VM and iterate until the outputs match — restoring the feedback loop that COBOL otherwise breaks.
Transactional workloads are fundamentally different. These are live environments serving real users in real time, where business logic is tangled between the COBOL application and the database across decades of accumulated state. There is no isolated environment to safely replicate them in, and no clean input/output pairs to test against. Autonomous migration of these systems remains out of reach for agents today — but tools like Windsurf can still help developers read, trace, and navigate transactional code across large COBOL estates, making developers work faster even where full automation isn't yet possible.
These two conditions define where agents can and cannot help with COBOL today. Understanding and enabling both is what has made it possible for Devin to find success where other agents have yet to.
Where Devin Helps Today
Documentation
At a Fortune 500 healthcare company, millions of lines of claims processing COBOL were written by engineers who had long since retired. With no COBOL experts left to interpret the code, the company needed a way to help business users understand how their own systems worked.
The company used DeepWiki, Cognition's codebase indexing tool, to build the system-wide map Devin needed to understand the codebase. DeepWiki parsed every program's structure, traced how memory blocks flow between programs, and built an interactive diagram that enables the developer to better understand the entire codebase.
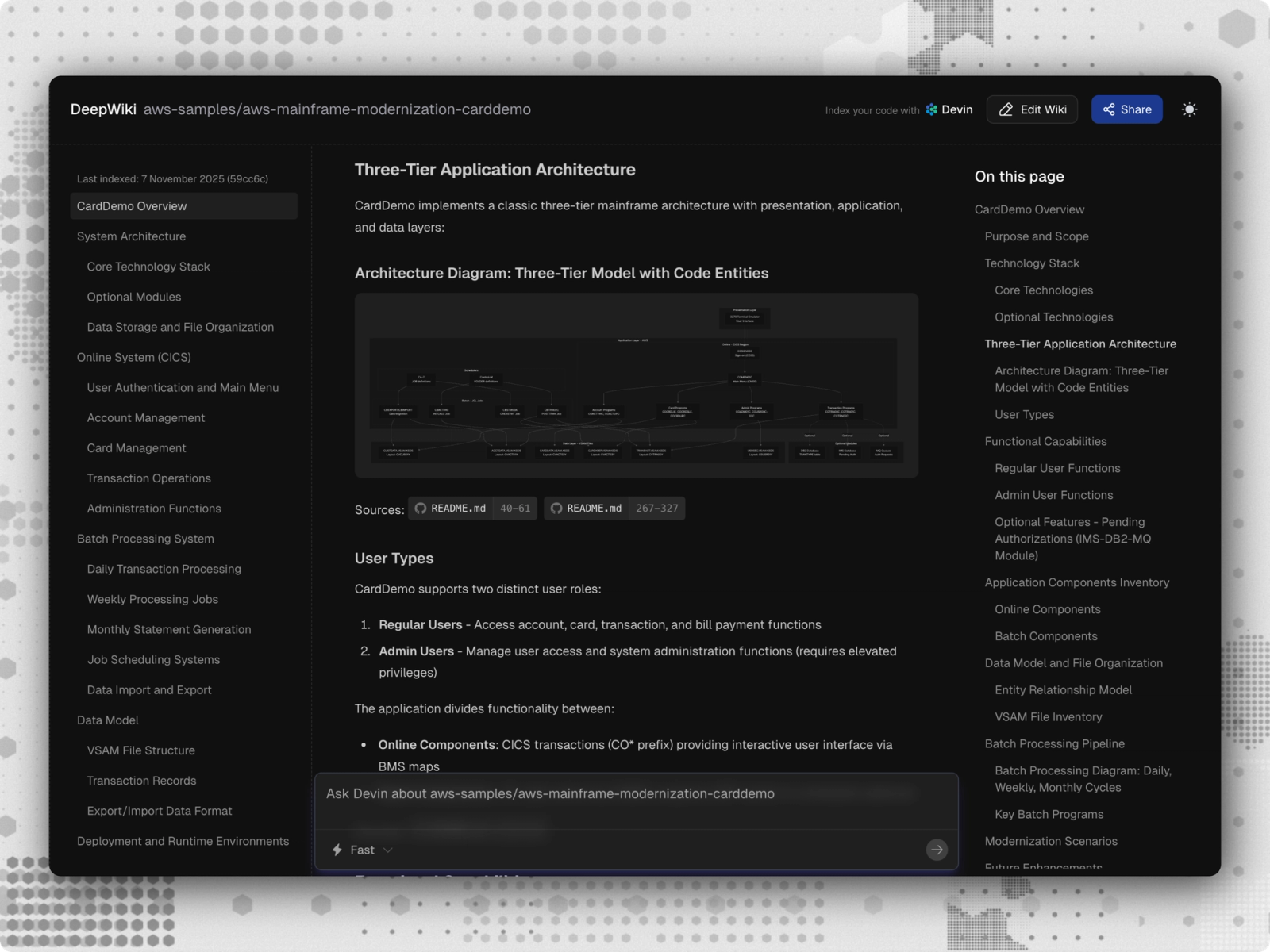
With a complete picture of how the system fit together, Devin approached each COBOL program as a functional piece of a live processing system — identifying what business problem each program solves, how it connects to the broader processing workflow, and what downstream payment systems it affects.
In one session, Devin identified that a program's recovery logic existed specifically to prevent duplicate transactions after a system interruption. For a company operating under strict regulatory oversight, that kind of discovery brought immediate value: a critical financial safeguard that was invisible is now documented, understood, and demonstrable to auditors.
The company now plans to document more COBOL in the coming months — recovering institutional knowledge that, without a system-wide map, would have remained trapped inside the code.
Batch Job Migrations
Documentation recovers the knowledge trapped in COBOL systems, but for many enterprises, the next step is getting the code off the mainframe entirely. A top 10 global automotive manufacturer came to Cognition with exactly that goal: migrating a 25,000-line COBOL customs workflow to AWS Lambda functions.

The migration was possible because this customs workflow was a batch workload. The company fed the COBOL input/output from the workflow directly to Devin, which analyzed the underlying logic, wrote a Python implementation designed to reproduce the same behavior, ran it on its VM, and tested it against the known outputs — iterating on every mismatch until the two converged.
Executing the migration accurately across the COBOL codebase required a playbook — a set of instructions encoding how Devin should complete the migration. Over time, the company refined that playbook using Devin's playbook editing capabilities. After each session, Devin identified what worked and what didn't, allowing it to refine ambiguous instructions, eliminate redundant steps, and tighten constraints.
Each session improved the next — the playbook got more precise, Devin's execution got more consistent, and the migration accelerated as a result. Within months, Devin completed the full migration — delivering an estimated 73% reduction in migration costs.
Large-Scale Refactoring
Itaú Unibanco, the largest private bank in Latin America, faced a government mandate to change their corporate tax ID from numeric to alphanumeric across their entire COBOL estate. While the code change itself was simple in theory, there is no way to search for the ID and "replace all.”
To scope the problem, the bank's COBOL experts used specialized mainframe tools to trace how data flowed through the system at runtime — tracking how fields change as they move between programs. That analysis surfaced roughly 20 distinct variations of how the corporate tax ID appears across the estate.
With the variations identified, the team tried other agentic tools to execute the changes. These agents had no understanding of COBOL's syntactic constraints — exceeding COBOL’s 72-character column limit and mishandling COMP variables. The result was code that broke when run on the mainframe, forcing engineers to monitor every session and manually correct errors, which defeated the purpose of using an agent.
Devin took a different approach. The bank's experts encoded every constraint — column limits, COMP handling, field-naming conventions — into a playbook. Where other agents blindly generated code that violated COBOL's rules, Devin followed the playbook on every change, respecting the same constraints the bank's own engineers would. And because Devin can run hundreds of agents concurrently, the changes were coordinated across the codebase in parallel rather than one program at a time.
The refactor was completed three months ahead of the government deadline — across hundreds of programs, 20 field variations, and zero production errors.
What’s Still Out of Reach
For now, autonomous transactional migrations remain beyond what agents can reliably do. Migrating these systems will likely require approaches like dual-write patterns, incremental module extraction, and gradually shifting traffic away from the mainframe. These are the kinds of specialized tools our field engineering team builds for our customers, and as this tooling matures, this remaining category of COBOL work will become accessible.
But for documentation, batch migrations, and large-scale refactoring, Devin has changed what’s possible. DeepWiki gives Devin a complete understanding of the codebase before it acts. Playbooks encode domain expertise so that understanding translates into consistent, accurate execution. And because Devin can run hundreds of agents in parallel, migrations can accelerate significantly — Itaú, for example, has completed migrations 5 – 6x faster without needing to scale headcount.
The bottleneck in COBOL modernization has always been talent. For the first time, enterprises have a path forward that doesn’t depend on closing that gap.
If you’re exploring a COBOL modernization and want to understand where Devin can help, reach out.








